A Trusted AI Compute Cluster for AI Verification and Evaluation
To verify and evaluate frontier AI systems, full access to internals might be needed, raising security concerns. A government-run Trusted AI Compute Cluster could provide a secure solution.

I wrote this last summer and thought it might be worth sharing. It assumes the potential for extreme risks from AI systems. The main idea came from thinking about how to best use a rather small investment in computing infrastructure. This isn't something I'd suggest blindly; it still requires careful thought and consideration.
Summary
-
Advanced AI systems could soon pose considerable dangers to public safety, such as through designing bioweapons and exploiting cyber vulnerabilities. To adequately address such risks, governments need to establish mechanisms for oversight of the most capable models.
-
A trusted AI compute cluster designed specifically for verifying and evaluating frontier AI development could help. With a focus not on training but on verification and evaluation, the cluster will house between 128 to 512 state-of-the-art GPUs, making it a cost-effective solution.
-
The verification and evaluation of frontier models may soon require full access to model internals, such as the model’s weights and training documentation. Since this level of access comes with severe security risks, such as model theft and the proliferation of dangerous capabilities, it requires a secure, government-operated infrastructure: a trusted AI compute cluster.
-
This cluster is committed to military-level information security — capable of defending against nation-state level threats. We suggest air-gapping the cluster, effectively severing it from external networks, and adopting security measures akin to those in a Sensitive Compartmented Information Facility (SCIF).
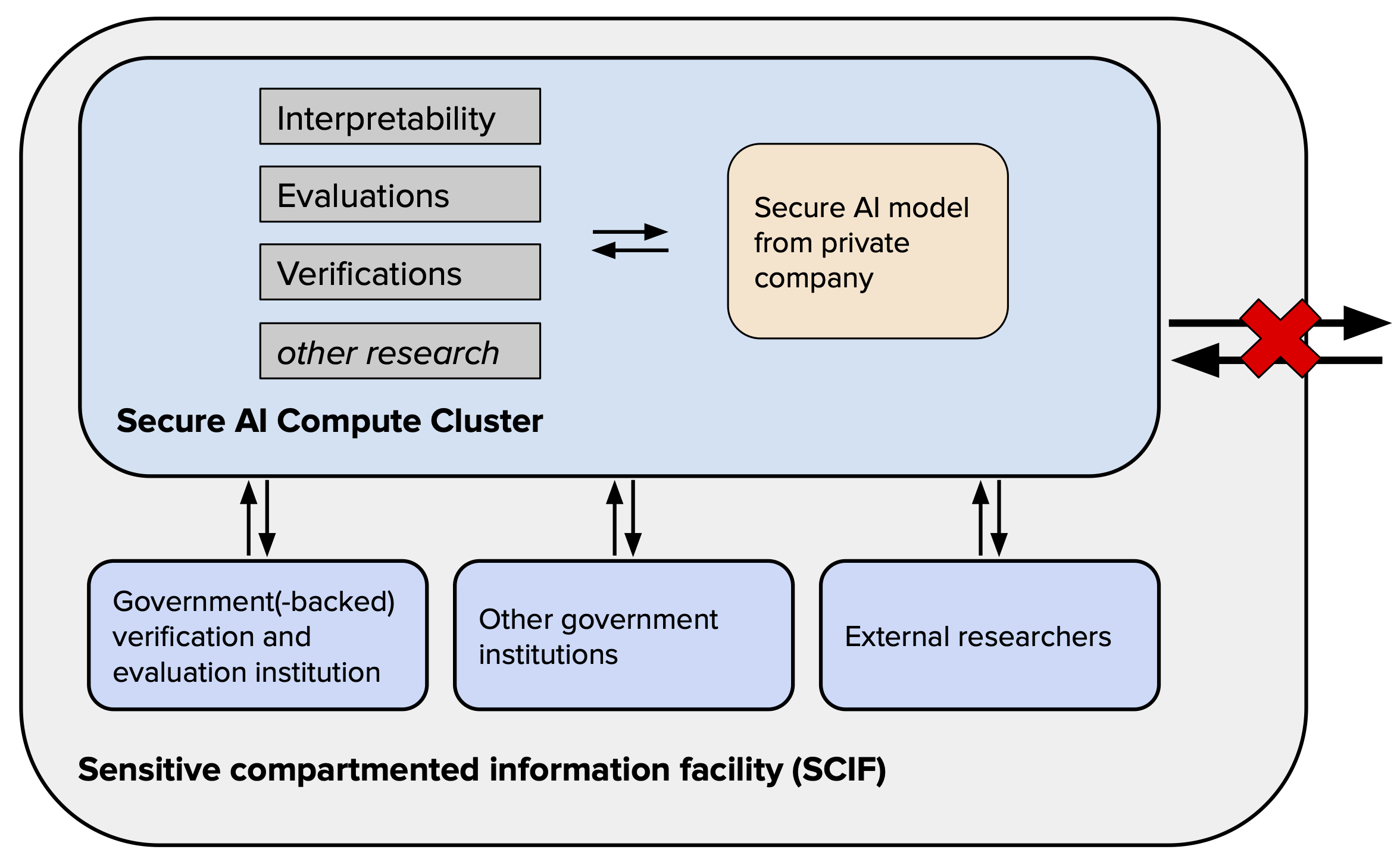
Figure 1: Overview of the Trusted AI Compute Clusters.
- Establishing a trusted cluster is both timely and advantageous for several reasons:
- Cost-effective: Only a small fraction of AI chips are needed compared to those used for training frontier models due to its narrow focus on verification and evaluation rather than training.
- Utilizing government expertise: Government institutions are uniquely qualified to provide a secure and trusted platform for handling confidential and sensitive data, such as proprietary AI models or red-teaming methodologies.
- Synergy with existing initiatives: The cluster would be a logical extension of the government-backed safety institutions as it would primarily serve evaluative and verification functions.
- International cooperation: A trusted cluster could be part of an international agreement on AI safety, used to independently verify the safety of models while protecting them from theft.
1. What’s a Trusted AI Compute Cluster for AI Verification and Evaluation?
We propose a Trusted AI Verification and Evaluation Cluster (TAIVEC) designed specifically for overseeing frontier AI development. Unlike the large compute clusters required for training AI models — consisting of over 2,500 H100 GPUs — this cluster would be compact, only housing between 128 to 512 state-of-the-art GPUs.[1]
The core functionalities of this cluster would include:
- Deployment of AI models secured from frontier AI companies to enable evaluations.
- Verification of claims and running proofs related to the models and commitments from frontier AI companies.
- Other tasks that require full model access, such as certain types of research, e.g., mechanistic interpretability research.
It would fill future governance gaps in AI verification and evaluation. We discuss these in more detail in the Appendix.
This cluster would facilitate the outlined functionalities for the following users:
-
Government or government-backed agencies evaluating AI models, including both existing (such as the intelligence community) and potentially new entities.
-
Potentially, external researchers, such as academics, conducting critical research that requires full-model access could additionally be authorized to access the cluster.[2]
A defining characteristic of this cluster is its commitment to military-level information security. The cluster is designed to securely host proprietary models, thereby preventing unauthorized access and potential model theft, while simultaneously facilitating rigorous research and external validation. In terms of security measures, the cluster would align with intelligence community standards, capable of defending against threats even at the nation-state level. We recommend air-gapping the cluster to further enhance its security, following protocols similar to those used in a Sensitive Compartmented Information Facility (SCIF).
Figure 1: Overview of the Trusted AI Compute Clusters. (Same figure as above.)
2. The Need for Military-Grade Security
The necessity for a trusted AI compute cluster is twofold: First, it allows the government to have full access to models from private actors for validation and evaluation purposes. Second, it offers a secure environment to prevent unauthorized proliferation and other associated threats.
The imperative for full model access
Currently, the dominant mode of evaluation is through API access provided by AI companies, but this requires trusting AI companies that the model available via their API is representative of the underlying model. How can one be certain of their claims?
As highlighted in this work, there will be situations demanding full model access. These include but are not limited to:[3]
- Ensuring the deployed system matches the system that was evaluated.
- Maintaining the confidentiality of a company's red-teaming strategy, particularly when national security is involved.
- Assurances against "man in the middle" attacks, where attackers intercept communications, especially when sensitive information is being transmitted.
- Conducting critical safety research that requires full model access, like mechanistic interpretability.
- Providing third-party validation for verifiable claims and proofs, which often requires computational resources to replicate parts of the training run.
As a consequence, for the areas where current API access methods are not sufficient, we proposed three options:
- Enriched API access in a privacy-preserving manner (e.g., as described in this OpenMined blog post).
- On-site access, comparable to a secure data room.
- Potential model transfers to trusted and secure compute clusters.
Although on-site access is a viable approach for some forms of evaluation and verification, it raises concerns about logistical inconveniences and the risk of hardware tampering, i.e., obfuscating information before inspectors visit. Therefore, the third option—model transfers to trusted and secure compute clusters—warrants serious consideration and is the focus of this post.[4]
Avoiding proliferation of proprietary and potentially dangerous models
Companies are understandably hesitant to grant full access to their models without stringent security measures in place. The risk of theft is not only a commercial concern but also a matter of national security, given the strategic importance and risk of misuse of AI technologies.
Moreover, there's an imperative to secure the cluster against models with dangerous behavior, such as models trying to infiltrate cybersystems or self-replicate, akin to computer worms. Since evaluation procedures may involve simulating potentially hazardous features for study—similar to "gain of function" research in biology—an air-gapped cluster is essential to mitigate risks.
Verifiable claims
Recent advancements in “proof-of” research—like proof of training algorithms or proof of data inclusion/exclusion—are becoming crucial for future governance. These mechanisms enable developers to make credible, verifiable statements about their development processes. For instance, they could serve as the foundation for a future non-proliferation regime[5], e.g., when developers are required to not train system above a certain threshold of computational resources. See the Appendix for more.
However, the successful verification of these proofs necessitates the availability of a secure and trusted compute cluster.
3. Timing and International Context on Establishing a Trusted Cluster
Implementing a trusted AI compute cluster is both timely and advantageous for several reasons: it is cost-effective, leverages existing governmental expertise, aligns with existing initiatives and addresses a future imperative.
Taking this step would position one as a frontrunner in creating the infrastructure that will be required for future international AI governance frameworks.
(i) Cost-effective
Compared to a full-scale data center designed for AI training, the proposed cluster requires minimal investment. Given its narrow focus on verification and evaluation rather than training, only a fraction of the AI chips are needed. Additionally, the operational uptime requirements are significantly less demanding than for conventional data centers. This makes the endeavor remarkably cost-effective.
(ii) Utilizing government expertise
The cluster would benefit from the government's unique expertise in information security and national security. Government institutions inherently offer a more secure and trusted platform for handling sensitive and confidential information, such as proprietary AI models or red-teaming methods that should not be publicly disclosed.
Furthermore, government organizations are adept at managing issues related to national security, which are increasingly relevant in the frontier of AI developments. This unique positioning could necessitate security clearance for certain staff members, further ensuring the cluster's security.
(iii) Synergy with existing initiatives
It would primarily serve evaluative and verification functions, making it a logical extension of evaluation safety institutions. We've previously identified the need for third-party evaluation institutions.
The cluster could be integrated into the government's overall evaluation and auditing infrastructure, potentially feeding its analysis into a review board responsible for model deployment approvals.
(iv) Addressing a future need
The trusted AI compute cluster is not just a contemporary solution but a forward-looking one. As we've discussed, reliance on API access alone is insufficient for ensuring transparent and accountable AI development. External auditing by a third party is crucial, as it cannot be done by the developer due to conflicts of interest.
Looking ahead, although a supercomputer may still be a few years from completion, this cluster can be thoughtfully designed and established in the interim. Given the rapid advancements in AI technology, there is some need for urgency.

Figure 2: Illustration of the GPT-X model weights being transported to the trusted cluster for evaluation and verification.
Appendix
A. Functions of the Trusted Cluster
More details and resources on the evaluation, verification, and other tasks.
Evaluations
Efficient deployment of secured AI models from frontier AI companies for evaluations.
- End-to-End Verification: The secure cluster ensures that outputs can be definitively attributed to specific AI models, mitigating the risk of fraudulent claims. This feature counters potential man-in-the-middle attacks where the direct connection between the API and the model might otherwise be unverifiable.
- Mitigating Security Risks in Red Teaming: The cluster securely handles evaluations involving sensitive prompts that could be hazardous if transmitted over the internet or to the model owner, thereby minimizing the risk of leaking sensitive information.
- Protection Against Dangerous Research Scenarios: The cluster is designed to safely conduct evaluations on high-risk capabilities. Analogous to "gain-of-function" research in biology, the environment is air-gapped to reduce the potential for unintended consequences, such as models with self-replicating behavior similar to computer worms.
- Fine-Tuning on Sensitive Data: To assess the risk of misuse from sophisticated actors, advanced safety evaluations could feature fine-tuning the model on highly sensitive data, such as databases of non-public cybersecurity vulnerabilities or lethal chemical substances. Such evaluations could only be conducted by authorized personnel, such as intelligence agencies, and would require extensive protection to avoid data leaks.
- Verification of Mitigation Measures: The cluster allows verifying the deployed model genuinely incorporates agreed-upon mitigation strategies. This could include testing for consistency between a model’s weights and its documentation, reviewing the training history and relationship between model versions, and ensuring the deployed model is identical to the model used during safety evaluations.
Verifications
Verification of claims and running proofs related to the models and commitments from frontier AI companies.
- In general, we try to address information asymmetry: The trusted cluster aims to resolve information imbalances that prevent the unwarranted proliferation of AI capabilities. It does so by providing a trusted environment for both parties, as the verification process may sometimes necessitate disclosing confidential information such as training data, model weights, and proprietary code.
- Proof-of-Training: The cluster enables robust verification of training transcripts and resultant model weights, offering both companies and external auditors confidence in a model's origin.
- Allows to replay segmented training data from transcripts to confirm that the final model weights align with expectations.
- Facilitates the execution of protocols that check the compliance of training transcripts with agreed-upon machine learning rules, such as performance metrics on benchmark tests.
- Proof-of-Inference: Companies can submit detailed, timestamped records of model inputs and outputs, as well as other critical metadata. The cluster can then recreate inference activities on a random selection of queries, ensuring the model's integrity.
- Includes a mechanism for replaying a random subset of inference queries to validate that the model and its weights have not been tampered with.
- Random Seed Verification: The cluster provides a mechanism for providing the initial random seeds to a developer, a mechanism often initially required to verify claims later. For example, it allows the trainer to pre-commit to certain seeds and hyperparameters of its training run, making the entire process verifiable and transparent.
Relevant resources
- Proof-of-Learning: Definitions and Practice, Jia et al., 2021
- [2303.11341] What does it take to catch a Chinchilla? Verifying Rules on Large-Scale Neural Network Training via Compute Monitoring, Shavit, 2023
- Tools for Verifying Neural Models' Training Data, Choi et al., 2023
Other tasks that require full model access
Other tasks that require full model access, such as certain types of research, e.g., mechanistic interpretability research.
- As the field of AI evolves, the cluster is equipped to adapt to new types of research that will require full model access.
- Already now, it could facilitate research, such as mechanistic interpretability research
- For additional perspectives and examples that elaborate on the need for full model access, see this Twitter thread.
For context, running a model like GPT-4 may require more than 45 H100s. However, we aim to stay ahead of future advancements, especially given the steady increase in model sizes (Villalobos et al., 2022). Seeking advice from leading AI tech companies would provide a more accurate projection. ↩︎
Similar to the "Federal Statistical Research Data Center" (FSRDC). The FSRDCs are partnerships between federal statistical agencies and leading research institutions. They are secure facilities that provide authorized access to restricted-use microdata for statistical purposes. By providing access to this data in a controlled environment, they allow researchers to conduct studies that inform public policy in a way that protects the privacy of individuals and establishments. Researchers can use the data to study a wide range of topics, from economics to public health, but cannot remove the data from the facility, ensuring data security and privacy. ↩︎
We discuss these in more detail in Appendix A. ↩︎
The recent proposal "National Deep Inference Facility for Hundred-Billion-Parameter Language Models" to the US NSF has some similarities. This post, in contrast, focuses more on the security of the infrastructure and the evaluation of models from private companies. ↩︎
Such a mechanism could facilitate international verification, enabling countries to validate each other's claims, thereby reducing social and political tensions. For the cluster to be universally trusted, it would need to be perceived as neutral. Future iterations of this proposal could consider establishing a 'neutral' secure cluster to meet this requirement. ↩︎