Training Compute Thresholds — Features and Functions in AI Regulation
Regulators in the US and EU are using training compute thresholds to identify general-purpose AI models that may pose risks. But why are they using them if training compute is only a crude proxy of risk?

Below is the executive summary of our published paper "Training Compute Thresholds: Features and Functions in AI Regulation." You can find the paper here and a Twitter summary here.
Abstract
Regulators in the US and EU are using thresholds based on training compute—the number of computational operations used in training—to identify general-purpose artificial intelligence (GPAI) models that may pose risks of large-scale societal harm. We argue that training compute currently is the most suitable metric to identify GPAI models that deserve regulatory oversight and further scrutiny. Training compute correlates with model capabilities and risks, is quantifiable, can be measured early in the AI lifecycle, and can be verified by external actors, among other advantageous features. These features make compute thresholds considerably more suitable than other proposed metrics to serve as an initial filter to trigger additional regulatory requirements and scrutiny. However, training compute is an imperfect proxy for risk. As such, compute thresholds should not be used in isolation to determine appropriate mitigation measures. Instead, they should be used to detect potentially risky GPAI models that warrant regulatory oversight, such as through notification requirements, and further scrutiny, such as via model evaluations and risk assessments, the results of which may inform which mitigation measures are appropriate. In fact, this appears largely consistent with how compute thresholds are used today. As GPAI technology and market structures evolve, regulators should update compute thresholds and complement them with other metrics into regulatory review processes.
Executive Summary
The development and deployment of advanced general-purpose artificial intelligence (GPAI) models, also referred to as “frontier AI models” or “dual-use foundation models”, pose increasing risks of large-scale societal harm (Section 1). Currently, these models develop ever higher capabilities through ever larger training runs, fuelled by ever more computational resources (“training compute”). But higher capabilities also mean higher risks to society, because many capabilities are dual-use (e.g., automated hacking capabilities) and because more capable models can be expected to be used more widely and relied upon more heavily, increasing the stakes if they fail or behave in undesired ways (e.g., producing biased outputs). As a result, regulators are increasingly using training compute thresholds to identify models of potential concern. This paper examines the key features of training compute and, accordingly, the functions training compute thresholds should have in GPAI regulation.
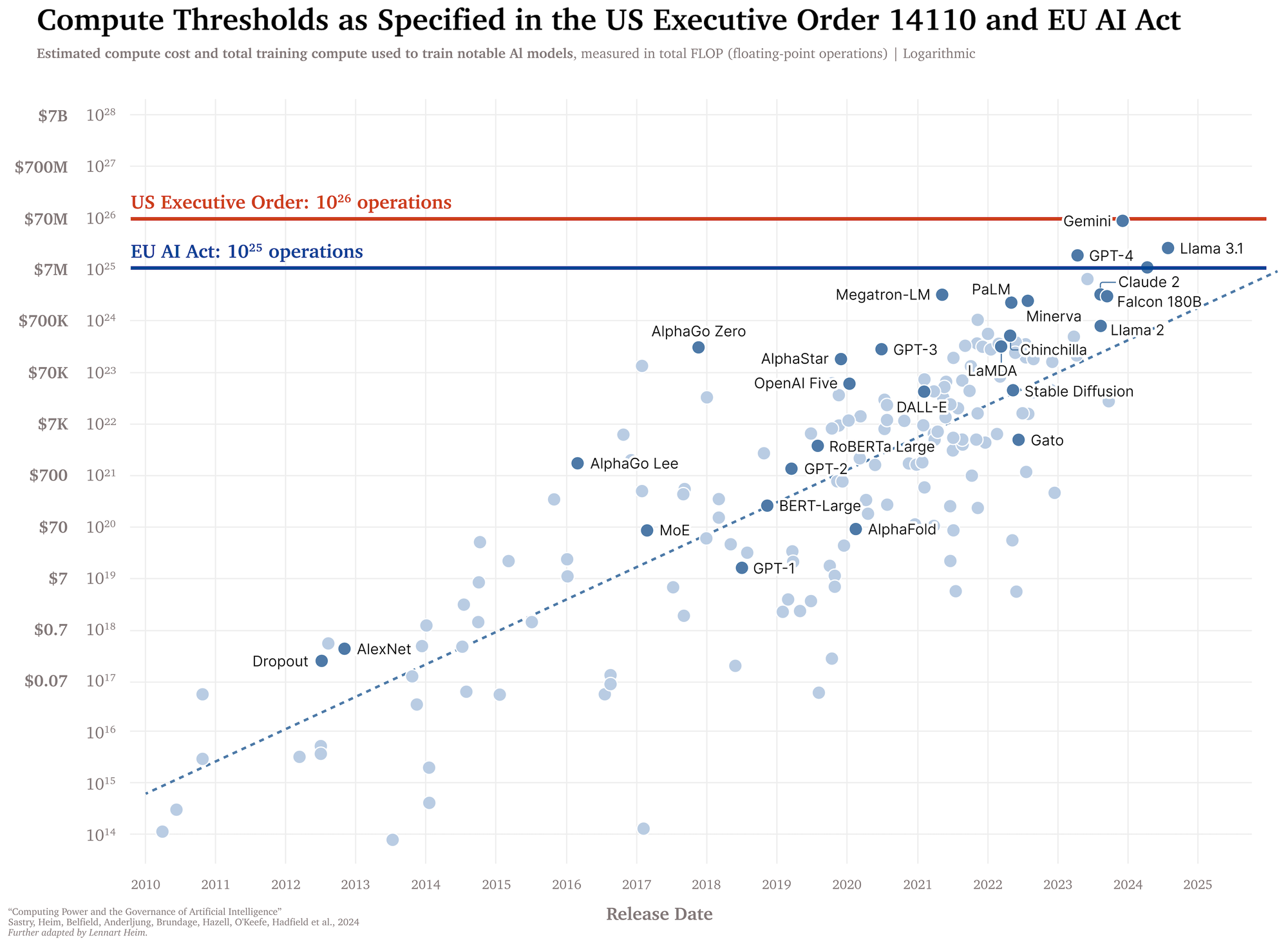
“Training compute” refers to the total number of operations a computer needs to perform to train an AI model (Section 2). In recent years, the scale of AI training has grown significantly, with increases in the amount of training data, the number of model parameters, and corresponding increases in the amount of compute required for training (Figure 1). “Compute” in this context refers to the total number of operations executed over the training process. While post-training enhancements like fine-tuning can significantly increase model capabilities, we recommend focusing on the compute used for the large training run (“pre-training”), as this aligns with empirical scaling laws and avoids impractical re-measurements for successive fine-tuning instances.
Training compute has several features useful for GPAI regulation (Section 3). In particular, it is:
- Risk-tracking: Training compute is indicative of a model’s loss, capabilities, and risks. Empirical research has identified correlations, known as scaling laws, between a model's training compute and its training loss, test loss, or validation loss. Improvements in loss tend to correlate with improvements in capabilities. As models become more capable, they may pose greater risks if they are misused or if they pursue misaligned objectives. The capabilities of a model also serve as a proxy for how widely it will be used and how heavily it will be relied upon and therefore the stakes if it fails or behaves in other undesired ways.
- Easily measurable: Training compute is a quantifiable metric that is relatively simple and cheap to calculate.
- Difficulty of circumvention: Training compute is relatively robust to circumvention attempts, as reducing the amount of compute used to train a model will generally decrease its capabilities and, consequently, lower its risks. This is because, for a given model architecture and training algorithm, the amount of compute used is directly related to the model’s capabilities and potential risks. While algorithmic efficiency improvements gradually reduce the amount of training compute required for a certain level of performance over time, this represents an incremental progression of techniques rather than an active circumvention.
- Measurable before development and deployment: Training compute can be calculated before the model is deployed, and estimated before the model is trained.
- Externally verifiable: The possibility for external parties, such as compute providers, to verify compute usage, without disclosing proprietary details, enhances compliance.
- Cost-tracking: Training compute is proportionate to the cost of computational resources for training, allowing the regulatory burden on smaller actors to be minimized while focusing on the most well-resourced ones.
Notwithstanding the advantages discussed above, training compute also has relevant limitations (Section 4). Fundamentally, it serves only as an imperfect proxy for risk. While high training compute generally indicates increased model capabilities and potential risks, some high-compute models may pose minimal concerns, whereas certain low-compute models could present significant risks (with the latter partially addressed through complementary non-GPAI regulations). Moreover, improvements in algorithmic efficiency are gradually reducing the amount of training compute required to achieve a given level of capability, potentially weakening the relationship between a specific compute threshold and the corresponding level of risk over time. However, this shift in the compute-risk correlation might occur gradually rather than abruptly as the field evolves.
Consequently, we suggest that compute thresholds should be used as an initial filter to identify GPAI models that warrant regulatory oversight and further scrutiny (Section 5.1). We argue that compute thresholds can and should have two primary functions: ensuring that regulators obtain sufficient visibility into risks of large-scale societal harm from GPAI models and that companies invest appropriate resources in understanding these risks. Precautionary mitigation measures can be based on compute thresholds too, but it should be allowable to later remove those mitigations if they turn out to be unnecessary.
However, compute thresholds alone should generally not determine which mitigation measures are ultimately required, given that compute is only a crude proxy for model capabilities and an even cruder proxy for risks of large-scale societal harm. Instead, to determine which mitigation measures are required, compute thresholds can be complemented with more precise but harder to evaluate thresholds based on other metrics, such as capability thresholds based on model capability evaluations. We also highlight that in a full regulatory framework for AI, most requirements should not hinge on the amount of training compute (Figure 2).
Both the US AI EO and the EU AI Act mostly use compute thresholds in line with our suggestions (Section 5.2 and Section 5.3). The US Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence mandates companies to notify the government about any ongoing or planned activities concerning the development of models that cross a compute threshold of 1026 operations, report on the measures taken to ensure the physical and cybersecurity of model weights, and share the results of red-teaming tests and mitigation measures taken based on those results. The EU AI Act requires providers of GPAI models that cross a compute threshold of 1025 operations to notify the European Commission, perform model evaluations, assess and mitigate systemic risks, report serious incidents, and ensure cybersecurity of the model and its physical infrastructure.
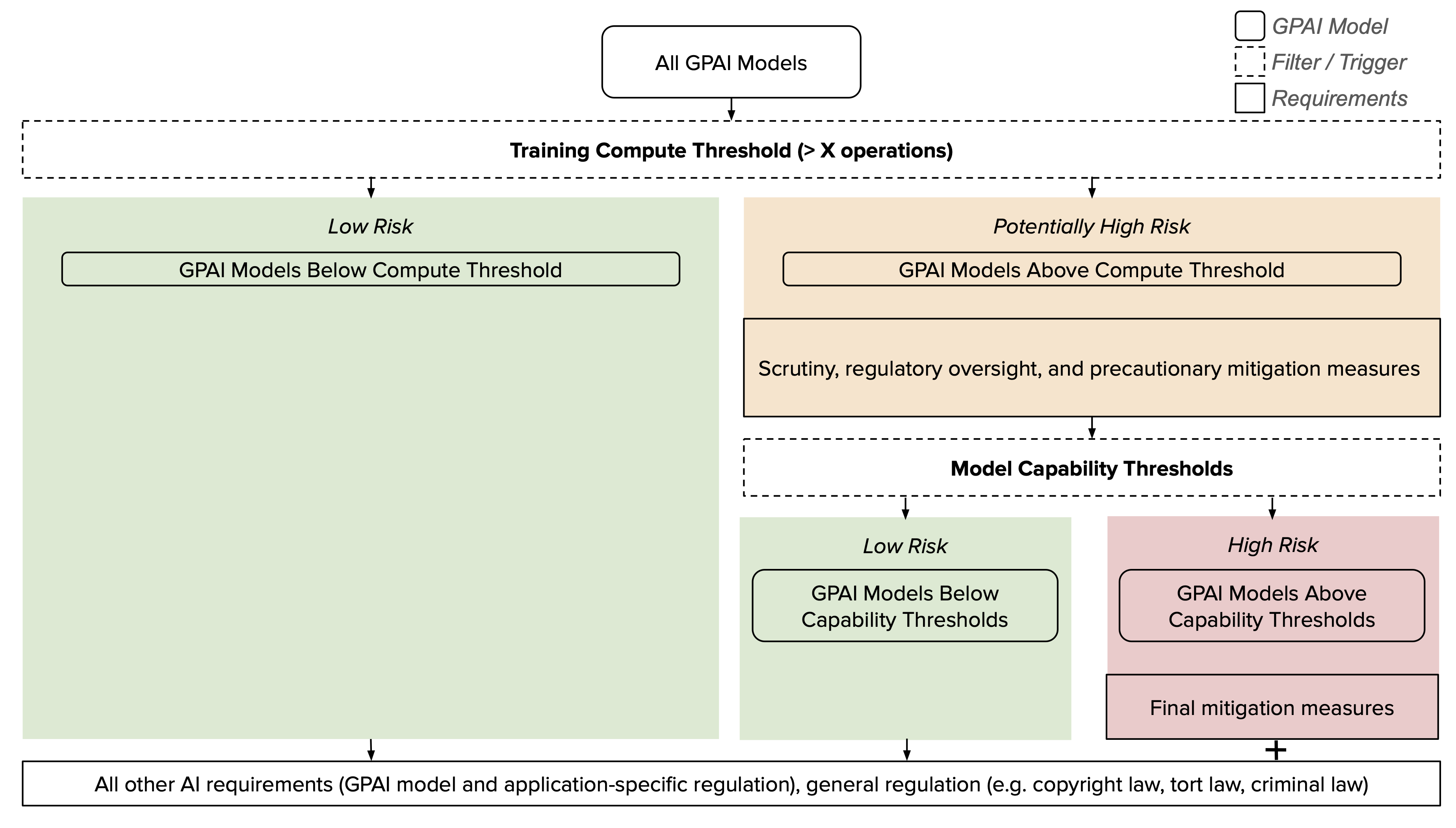
Challenges remain in effectively leveraging compute thresholds for GPAI regulation (Section 6). A key question is the appropriate threshold level. There is high uncertainty about the risk stemming from current and future GPAI models trained on different amounts of compute. As a result, a low threshold may be overinclusive, while a high threshold may be underinclusive. Moreover, the direction in which a compute threshold should move over time is not obvious, and it can make sense to complement compute thresholds with other metrics. For example, increasing algorithmic efficiency allows more capable models to be trained with less compute. A reason to consider adjusting the compute threshold downwards over time.
However, there are also reasons to adjust the compute threshold upwards If better understanding of GPAI models reveals that models that are in scope of a given compute threshold pose limited risks, the compute threshold should be raised to focus on potentially risky models. With improving algorithmic efficiency and computational price-performance, an increasing number of less well-resourced actors may fall within the scope of a given compute threshold, making the requirements increasingly burdensome and oversight increasingly costly. Other relevant factors include the offense-defense balance of AI systems (i.e. whether an AI system offers greater advantages for offensive or defensive applications), the threat landscape (i.e. the number, capacity, and willingness of malicious actors to use AI systems), and societal vulnerability or adaptation (i.e. the ability and capacity of society to deal with attacks, failures, and emergencies, e.g., through competent, well-resourced, and stable institutions).
Some other metrics, such as risk estimates, model capabilities, and effective compute, are better proxies for risk. However, these metrics are much harder to measure than training compute is. Complementing mere compute thresholds with other metrics becomes relevant to the extent that scaling laws cease to hold and training compute becomes a worse proxy for risk. Particularly relevant combinations may include training compute and model capability evaluations (to ensure catching the most capable models) and training compute and number of users (to ensure catching the most widely used models). However, any threshold that is supposed to serve as an initial filter to identify models of potential concern should be based on metrics that can be measured easily and early in the model lifecycle. This, at least currently, excludes risk estimates and model capability evaluations, and at least before deployment, the number of users.
Overall, while not perfect, compute thresholds are currently a key tool in GPAI regulation (Section 7). In particular, compute thresholds are currently the best tool available for identifying potentially risky GPAI models and triggering regulatory oversight and further scrutiny. They are based on a risk-correlated, quantifiable metric that is difficult to circumvent and can be measured before model development and deployment, enabling proactive governance efforts. Compute thresholds can complement more targeted filters like model capability evaluations that ultimately determine which mitigation measures are required.
Edit history:
August 6th, 2024: This blog post previously covered my working paper on this topic. It has now been superseded by v2, whose summary is above. The complete paper can be found here.