This can't go on(?) - AI Training Compute Costs
The current progress in increased compute spending, driven by the training of frontier AI systems, is not sustainable as it currently outpaces the reduction in compute price performance.

Naively extrapolating AI training compute costs into the future.
The current progress in increased compute spending, driven by the training of frontier AI systems, is not sustainable as it currently outpaces the reduction in compute price performance. Estimating the limits of this trend can be done via extrapolating the current trends in training compute and the reduced cost of compute over time. According to Sevilla et al. (2022), the training compute of machine learning systems is doubling every 6 months. Furthermore, the price per computational performance is decreasing over time, with a halving time for GPUs estimated at every 2.5 years (Hobbhahn & Besiroglu, 2022).
Assuming the training cost of PaLM (Chowdhery et al., 2022) was approximately $9 million (Heim, 2022), the projected cost in Δt years from 2022 can be calculated as:
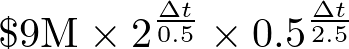
Notably, this projection reveals a significant contrast: compute needs are expected to double twenty times, resulting in growth by a factor of one million, while the cost of compute is projected to halve only five times, reducing the cost per compute by a factor of 32.
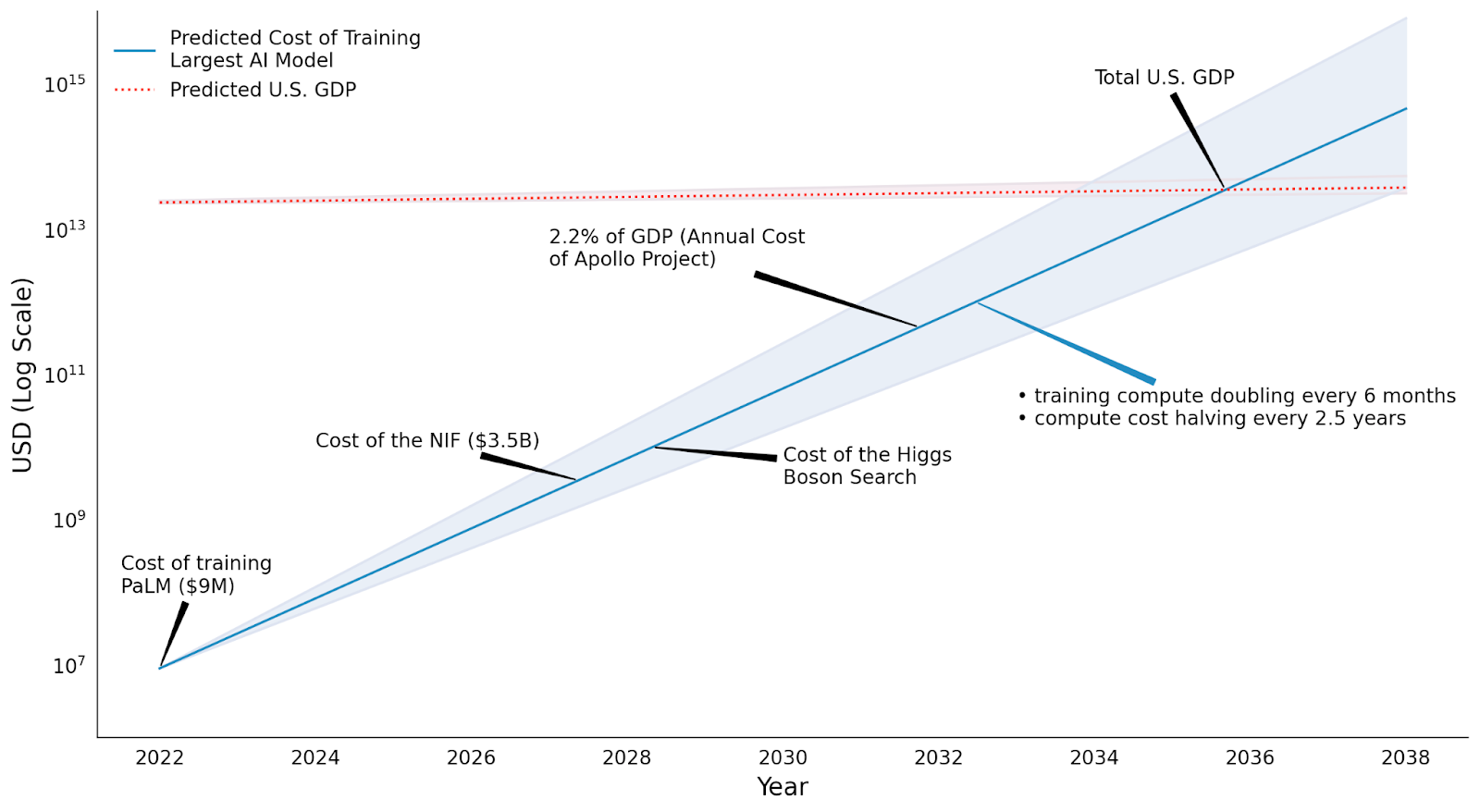
Thus, around the year 2032, the total cost of a system would be equivalent to 2.2% of the US GDP (approximately $700 billion) and would be comparable to the previous annual cost of running the Apollo project (we assume yearly GDP growth of around 3%).
However, it is important to clarify a misconception regarding the role of algorithmic progress (Erdil & Besiroglu, 2022). In our analysis, we focus on the training compute trend rather than the "capabilities trend". Although algorithmic efficiency enables us to achieve 'more capabilities per compute,' it is crucial to note that this aspect is already taken into account within the compute trend itself (and we are not measuring the resulting capabilities). If compute doubles every 6 months, then your capabilities grow with the scaling from the increased training compute, and the improved algorithmic progress.
Ultimately, our primary concern lies in the amount of compute used and its associated costs. Algorithmic efficiency, while increasing capabilities per compute, does not directly result in cheaper compute costs – but it results in cheaper capabilities per compute.
This method is based on Lohn & Musser (2022) but incorporates updated data on the discussed trends. It should be noted that all the caveats mentioned in Cotier (2023) apply:
• The cost estimates have large uncertainty bounds—the true costs could be several times larger or smaller. The cost estimates are themselves built on top of estimates (e.g. training compute estimates, GPU price-performance estimates, etc.).
• Although the estimated growth rates in cost are more robust than any individual cost estimate, these growth rates should also be interpreted with caution—especially when extrapolated into the future.
• The cost estimates only cover the compute for the final training runs of ML systems—nothing more.
• The cost estimates are for notable publicly known ML systems according to the criteria discussed in Sevilla et al. (2022, p.16). The improvements in performance over time are irregular—this means that a 2x increase in compute budget did not always lead to the same improvements in capabilities. This behavior varies widely per domain.
• There’s a big difference in what tech companies pay “internally” and what consumers might pay for the same amount of compute. For example, while Google might pay less per hour for their TPU, they initially carried the cost of developing multiple generations of hardware.