The Case for Pre-emptive Authorizations for AI Training
Extending the regulation of frontier AI systems to potentially deny specific training attempts is an ambitious proposal that asks for a substantial burden of proof.

Ensuring safer outcomes right from the production floor.
This piece reflects my personal opinion and was quickly drafted in response to recurring discussions I had. It is not meant to serve as an exhaustive exploration of the topic, but instead, a brief overview highlighting key arguments I frequently refer to.

Extending the regulation of frontier AI systems to potentially deny specific training attempts is an ambitious proposal that asks for a substantial burden of proof. Why would we consider it necessary to prevent an AI system from even being trained, especially when our regulatory focus is often on the deployment of technologies? After all, we are not aware of the specific risks of an AI system when it has not yet come into existence. Despite these concerns, I argue that “pre-emptive authorization” is warranted due to (i) the risk of proliferation, (ii) potential dangers arising during the training run, and (iii) practical benefits related to the compute moat.
More concretely, I envision a regulatory framework where AI developers would need to secure a permit before they're allowed to train frontier AI systems.[1] This permit would be evaluated on two factors: the level of responsibility demonstrated by the AI developer (Schuett et al., 2023)[2] and the properties of the training run.[3]
This approach to regulation is not unprecedented. We find parallels in other disciplines such as biology, where approvals are frequently mandated before experiments. Moreover, one can draw comparisons with the stringent controls placed on the construction of nuclear weapons (Baker, 2023). Ultimately, I’m discussing a mechanism that would apply to only a few actors (e.g., big tech companies).
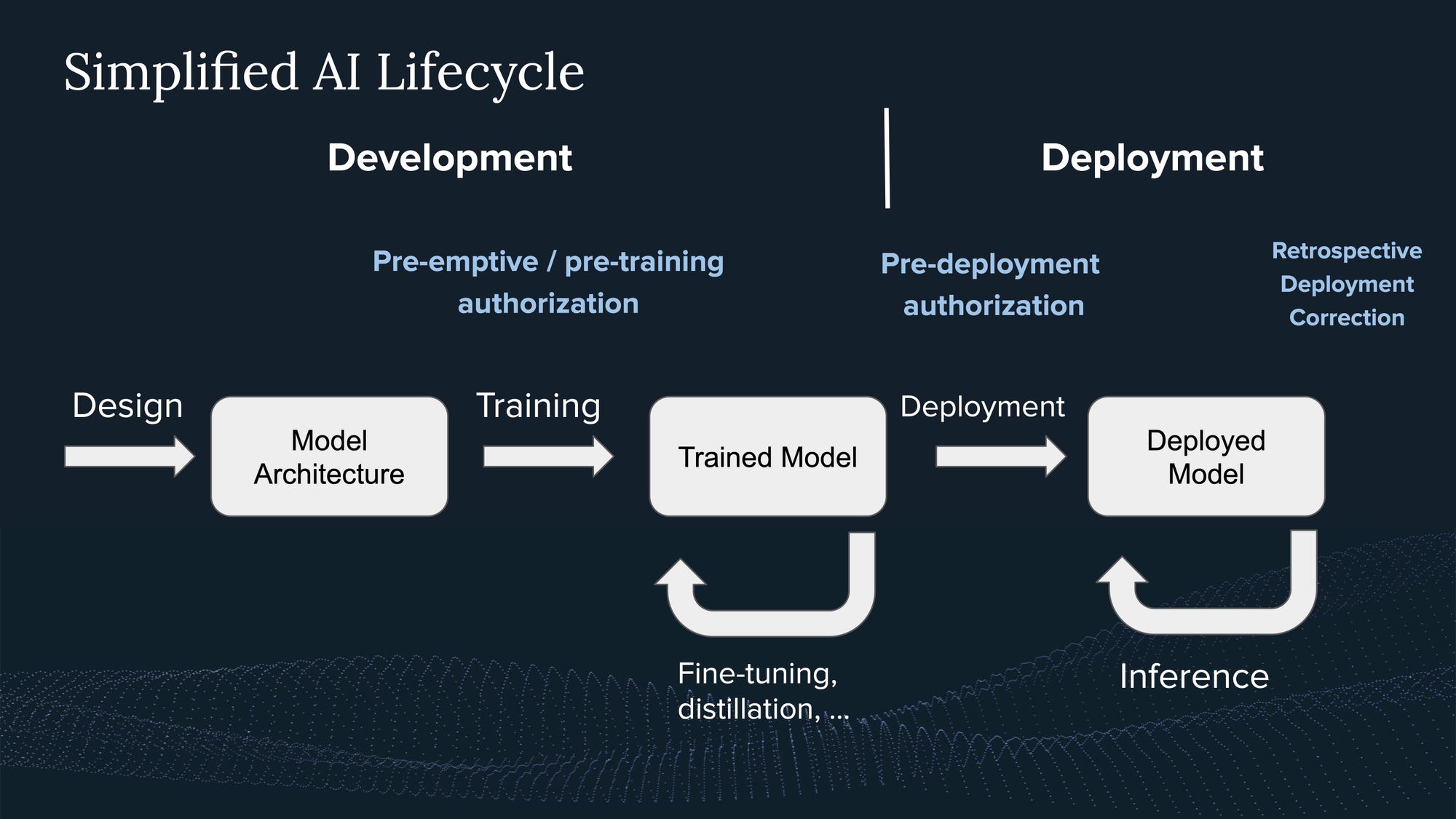
Gaining an understanding of the lifecycle of AI systems and their governability helps to frame the discussions around pre-emptive authorizations (Figure 1). Some may argue that an AI system only leads to negative impacts when deployed; however, I argue that this perspective needs reevaluation. I see three primary reasons in support of this regulatory step:
(i) Proliferation risk
First, there is a proliferation risk associated with trained AI models. Even if a model is not intended for a public release, such as GPT-4, it could still be stolen via hacking (Ladish & Heim, 2022; Cottier, 2022). Once a model falls into the wrong hands, controlling its misuse becomes an almost impossible task (Anderljung & Hazell, 2023). The previous “moats”—like the vast amount of compute, data, and tacit knowledge required—are bypassed. Furthermore, consider a scenario where a model undergoes a pre-deployment verification and fails due to safety concerns. Even in such a case, the model could still be stolen and deployed by a less cautious actor.
(ii) Potential dangers arising during the training run
The second concern revolves around the potential dangers that could emerge during the training process itself, especially as we continue to scale models at the current pace.[4] There's a possibility, for example, that a model could inadvertently develop situational awareness during training (Shevlane et al., 2023, Ngo et al., 2022; Cotra, 2023), or start “gradient hacking”, a phenomenon where a system intentionally manipulates its learning process to preserve certain objective or biases (Hubinger, 2019).[5] Imagine an AI model that has gained an understanding of its environment during training, and starts to optimize for its own goals, independently from the guidelines set by its developers, and starts seeking power (Carlsmith, 2021).
(iii) Practical benefits, i.e., compute governance
Thirdly, we have to consider the practical aspect of pre-emption, particularly in the context of “mere software”[6] where regulation, especially verification and enforcement, can be challenging. Apart from the risk mitigation benefits, pre-emptive authorization can serve as an effective point of intervention, given the significant compute requirements of AI training. This is related to the idea of compute governance, where compute serves as a unique governance lever compared to other AI inputs such as data and algorithms. This lever is the most potent during the training run (although it's not the only aspect of compute governance to consider) (Heim, 2023; forthcoming paper “Computing Power and the Governance of Artificial Intelligence”).[7] Even in a hypothetical scenario where there's no proliferation risk, this point underlines the practicality of pre-emptive intervention because of the enhanced governance capacity prior to the system’s training due to compute.[8]
Concluding thoughts
The concept of authorizing the training of certain AI systems may sound drastic. However, it may also represent one of the most effective actions we can take in this fast-paced domain. My proposition isn't about denying all frontier training runs pre-emptively, but rather instituting a governance system of authorization based on the level of responsibility of the AI developer and properties of the training run.
There's a growing consensus around the necessity of pre-deployment authorizations (Mökander et al., 2023; Schuett et al., 2023), and I propose to extend this practice to the development stage. At the very least, we should strive to establish the required infrastructure to support such a shift in the near future (e.g., by equipping compute providers with the required tools, such as detecting and verifying these training runs).
Acknowledgment: Thanks to everyone who has engaged in discussions on these ideas with me over the past year.
One could, for example, classify frontier systems as systems that require more than 1e26 FLOP training compute and/or other criteria. I’m not arguing that current systems should undergo this regulation. ↩︎
Notably, we cannot evaluate the capabilities of the system itself, as it does not exist yet. However, we can evaluate the developer and if they follow best practices for the development of safe AI systems. Schuett et al. (2023) discuss some propositions that make an AGI lab less or more responsible. ↩︎
I imagine a process wherein we evaluate the properties of the training run, such as hyperparameters and architecture, ideally in a manner that preserves intellectual property (IP) rights. More research is warranted. ↩︎
These arguments are not exhaustive, and there are gaps in our understanding that need further exploration. When I started writing this paragraph I was expecting to find a more detailed exploration of this in the literature, but I couldn't. ↩︎
As a baseline, certain architectural features could be identified that may increase the likelihood of such hazards emerging. For instance, architectures incorporating a reinforcement learning component might pose more risks than those without (Turner et al., 2019). ↩︎
Essentially, an AI model is just a complex large algorithm on a computing system which makes it rather less excludable, and therefore less governable ↩︎
In addition, pre-emptive authorization could have significant financial benefits for developers. Initiating a constructive dialogue before embarking on a costly training process could save millions. It would be unfortunate for a government to later deny permission to deploy an AI system after significant investment has been made. Therefore, a preliminary discussion could be beneficial for all parties involved. ↩︎
However, the case for this approach would be less compelling in the absence of a proliferation risk. ↩︎