Estimating 🌴PaLM's training cost
How much did Google's 530B parameter model PaLM's training cost? Something around $9M to $23M.

tl;dr What would it cost you to train PaLM using cloud computing (and you're not Google)? Something around $9M to $23M.
PaLM a 540B state-of-the-art language model
Google recently published a new paper presenting PaLM (their blogpost) – a 540B parameter large language model.

ML model training compute has been skyrocketing and so have the connected costs paying for the required computing resources (short "compute"). In our last paper, we found an astonishing growth of a factor of 10 Billion since 2010 in the training compute for milestone ML models – doubling every 6 months.
PaLM is now the new king of the hill. 👑
| ML Model | Training Compute [FLOPs] | x GPT-3 |
|---|---|---|
| GPT-3 (2020) | 3.1e23 | 1x |
| Gopher (2021) | 6.3e23 | 2x |
| Chinchilla (2022) | 5.8e23 | 2x |
| PaLM (2022) | 2.5e24 | 10x |
So how much did the final training run of PaLM cost? Let's explore this. Note that a bunch of caveats apply which I discuss at the end.
The "facts"
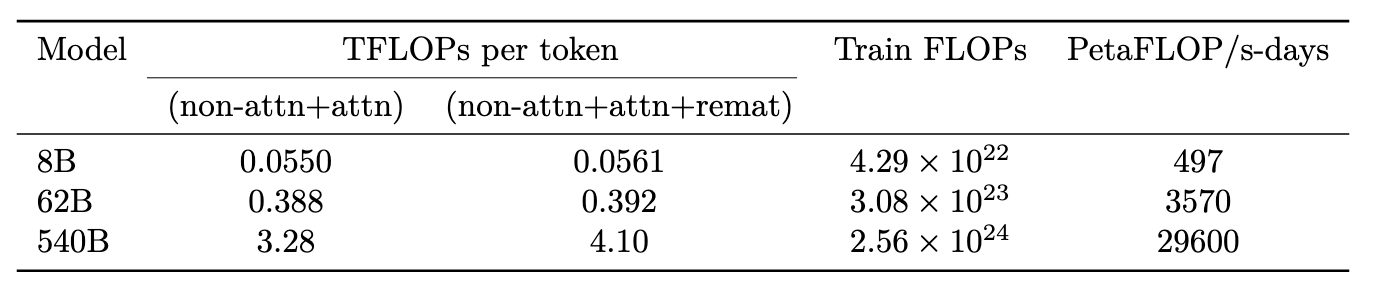
The final training run of PaLM required 2.56×10²⁴ (2.56e24) FLOPs.
Also,
We trained PaLM-540B on 6144 TPU v4 chips for 1200 hours and 3072 TPU v4 chips for 336 hours including some downtime and repeated steps.
That makes a total of:
- 2.56×10²⁴ FLOPs
- or 8'404'992 TPUv4chip-hours (each chip contains 2 cores = 16'809'984 TPUv4core-hours)
- or 64 days.
Also, they mention their TPU utilization, in Appendix B it says:
The training of PaLM 540B uses rematerialization because the feasible batch size with rematerialization enables higher training throughput. Without the rematerialization costs, the resulting model FLOPs utilization is 45.7% without self-attention ((238.3×6×540)/(275×6144)) or 46.2% with it. PaLM’s analytically computed hardware FLOPs utilization, which includes rematerialization FLOPs, is 57.8%.
If you're wondering what utilization is, we've discussed it in detail in our Estimating Training Compute article. I'll also use our second method presented in the linked article.
Two estimation methods
Now, we have two methods:
-
Using the 2.56×10²⁴ FLOPs for the final training run.
- We can estimate the cost per FLOP from renting a TPU instance (assuming the above utilization rate).
- We can also estimate the costs by extracting the cost per FLOP from other cloud providers (e.g. ones using NVIDIA A100's).
-
Using the 8'404'992 TPUchip-hours
- We can then look up the hourly rent for a TPU-chip.
While method 2 seems to be favorable (as we need to make fewer assumptions about the utilization), unfortunately, TPUv4 prices are not accessible without asking for a quote.

Therefore, let's learn about the costs of renting the previous version of TPUs and how many FLOPS they provide.
(a) Renting TPUv3 via Google Cloud
We can rent a TPUv3 pod with 32 cores for $32 per hour. So, that's one TPUcore-hour per dollar.
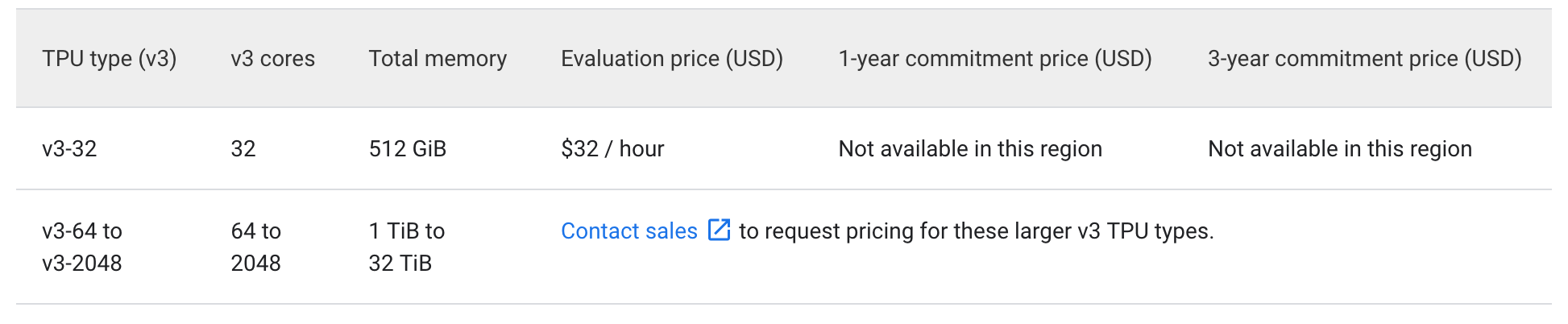
Using our above 16'809'984 TPUv4-core hours, we get an estimate of around $17M if we substitute TPUv4 with a TPUv3.
On the one side, this is an underestimate, as a TPUv3 is less performant than TPUv4 and we'd require more time or TPUs.
On the other side, we have usually seen that prices stay roughly constant while one gets more performance. Therefore, if Google Cloud would ask roughly the same price for the TPUv4 as for the TPUv3 then this estimate is fair. If they would ask for less then the real cost would be lower. If they'd ask for more the real costs are higher.
(b) Cost per FLOP
We know a TPUv3 chip provides around 123 TFLOP per second (TFLOPS) for a bfloat16 (Table 3). Nonetheless, that's the performance from a specification sheet and displays the peak performance.
This peak performance needs to be adjusted by the utilization factor. As outlined above, they achieved an astonishing 57% (our previous estimate for people trying hard was around ≈30%).
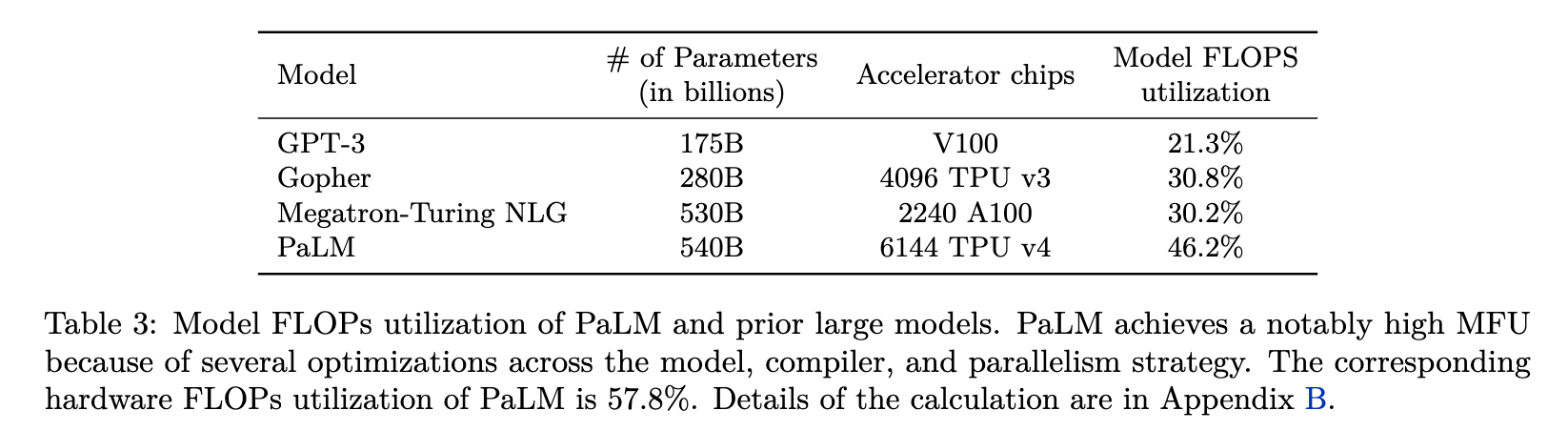
I'd therefore assume around 50% for using TPUv3:
0.5 x 123 TFLOP per second per chip x 0.5 chip-hour per x 60x60 seconds per hour $ = 110.7 PFLOPs per $.
That get's us 221 PFLOPs per $. Now using the presented 2.56×10²⁴ FLOPs for the final training run, we get:
2.56e24 FLOPs / 110.7e15 FLOPs per $ = 23,125,564.59 $.
That's $23.1M.
(c) Using an NVIDIA V100
We can just follow the same reasoning as in this blog post by LambdaLabs. There they assume a V100 cloud instance rented via their service. As GPT-3 used 10x less compute than PaLM, we'd estimate $46M for the final training nun.
Nonetheless, this post is two years old and uses an NVIDIA V100. An NVIDIA A100 is already one order of magnitude more performant (Tensor performance).
Therefore, addressing for 10x more performant hardware but assuming an utilization of 50% gets us around $9.2M.
Conclusion
Our three (not independent!) methods estimate $17M, $23.1M, and $9.2M for the final training cost of PaLM.
Caveats
- Of course, Google didn't pay that much. They own the hardware. This assumes the costs to an end-consumer paying Google Cloud for renting TPUv3 pods.
- Longer commitments to renting a TPU pod would get you a discount (1-year 37% discount).
- We don't have the costs for TPUv4 and we used the TPUv3 instead.
- This assumes you know how to efficiently utilize a TPUv3 pod up to a 50% utilization rate. That's an astonishing rate.
- We only talk about the cost of the final training run. This does not include all the other hard (and costly) things, such as engineering, research, testing, etc.
- much more
Thanks, Malte for the initial estimates, and Anson for spotting a mistake!
ps. If someone has some insights on the costs for TPUv4, I would appreciate some hints.
Update 05 June 2022: The original post estimated $11.6M in (b) which is wrong. It's 2x $23.1M. One gets one core hour per $ which translates to 0.5 chips hour per $ (and we specifications for the performance per chip).
Thanks Malte for the hint!