Inference Compute: GPT-o1 and AI Governance
GPT-o1 demonstrates how leveraging more compute at inference time can enhance AI reasoning capabilities. While this development is incremental rather than revolutionary, it underscores the growing importance of inference compute in AI impacts and governance.

I've received some inquiries about the implications of GPT-o1, dubbed "strawberry.” This post captures my initial thoughts on how it relates to previous work and its potential impacts. As always, these views are evolving and subject to change as we learn more. While there's much more to discuss, I'm erring on the side of sharing some preliminary thoughts.
Summary
- Researchers have found another way to increase AI capabilities: GPT-o1 leverages additional compute at inference time to reason and produce better answers, continuing the upward trend in AI capabilities.
- This development is an incremental improvement, not a paradigm shift. We've seen inference compute leading to better capabilities before, with chain-of-thought reasoning being a prime example.
- Increased inference compute is complementary to training compute, not a replacement. Larger pre-trained models still have an edge when given access to the same inference techniques, both aspects remain critical for advancing AI capabilities.
- Existing approaches to AI governance and policy remain valid. There are no major implications; rather, we're seeing a gradual shift that was observed before: an increased importance of inference compute that highlights the growing significance of post-training enhancements.
- Inference compute is increasingly important for AI governance, as it determines the scale of deployment. All things equal, a bigger scale might mean bigger impact. For example, in a surveillance state, the scale of misuse (i.e., how many people can be surveilled) using multimodal AI systems is determined by available inference compute. In terms of economic impact, inference compute determines the number of AI workers or agents operating in the economy.
- This development doesn't fundamentally challenge how training compute thresholds are being used right now. However, it highlights the general need for carefully designing thresholds, including safety buffers, and implementing ongoing updating processes.
- As AI capabilities continue to advance, it becomes increasingly challenging to make informed governance decisions from an outside perspective, underscoring the need for improved access to technical details or closer collaboration between researchers, industry, and policymakers. Many open questions remain, particularly regarding the specifics of the reasoning process. There is an increasing need for more technical insights to inform policy decisions, especially concerning model evaluation, oversight, and technical aspects of AI governance.
Introduction: Another Turn of the AI Capability Ratchet
GPT-o1's release has prompted many questions about its implications. While it's important to stay updated about AI advancements, it's crucial to maintain perspective. If a single development were to invalidate all existing AI governance and policy approaches, it would indicate a fundamental flaw in policy-making.
The main takeaway should be that researchers have found another complementary way to increase AI capabilities. The capability curve continues its upward trajectory. This time, instead of solely increasing training compute, developers have leveraged more compute at inference time to improve the model's reasoning. This shift towards leveraging inference compute represents a new frontier in AI capability enhancement. While significant, this development does not fundamentally alter current policies. It does, however, reinforce the need for ongoing flexibility and adaptability in policy approaches.
I've been thinking about inference compute's role for a while. Let's go through what GPT-o1 is, its high-level technical implications, my previous thoughts on inference compute, some governance implications, and the unresolved questions I have.
GPT-o1: Scaling Laws for Inference?
GPT-o1 is OpenAI's latest GPT model. Its key innovation is enhanced reasoning capabilities through a chain-of-thought process. This allows the model to "think" before answering, leading to better responses across various tasks. The model does this by generating additional tokens not visible to the user. These hidden tokens represent the model's step-by-step reasoning. More thinking means more tokens, which requires more compute. This increased compute translates to better performance on benchmarks and tasks.
What we're seeing resembles the scaling laws we know from training, but applied to inference. More compute allocated to this reasoning process correlates with better model performance. While it's premature to call these observations "laws," we're seeing inference scaling.
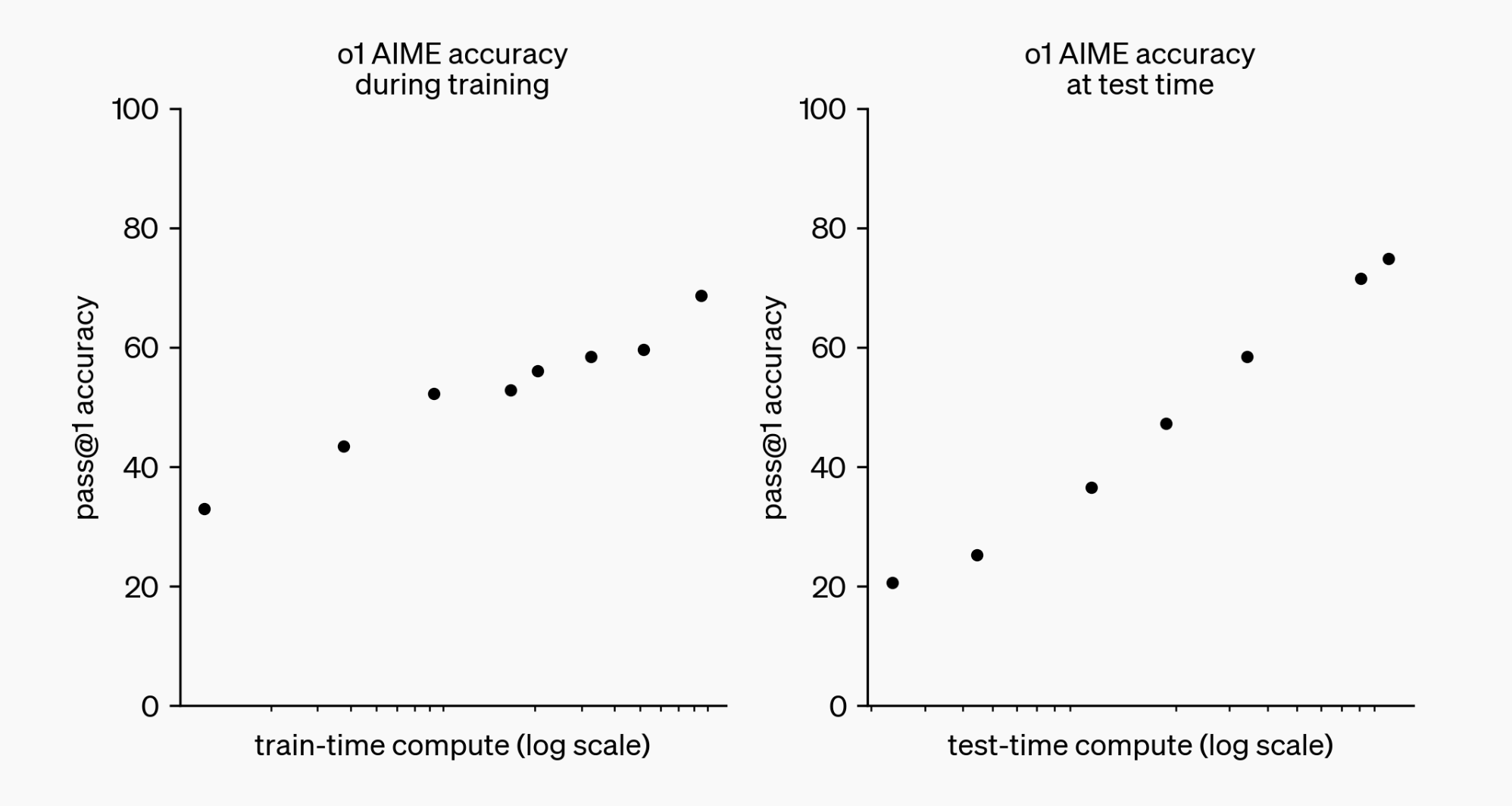
From OpenAI.
Incremental Progress, Not Paradigm Shift
While GPT-o1 is impressive, it's not fundamentally new. This development is an incremental improvement, not a paradigm shift. We've seen inference compute boost capabilities before, such as in earlier chain-of-thought implementations. Some previously called this process "unhobbling," while others referred to it as "post-training enhancements." The concept of trading off training compute and inference has also been previously discussed (there is a lot of alpha in reading Epoch’s research). What's notable here is how OpenAI has refined and scaled this approach, pushing the limits of inference-time compute use.
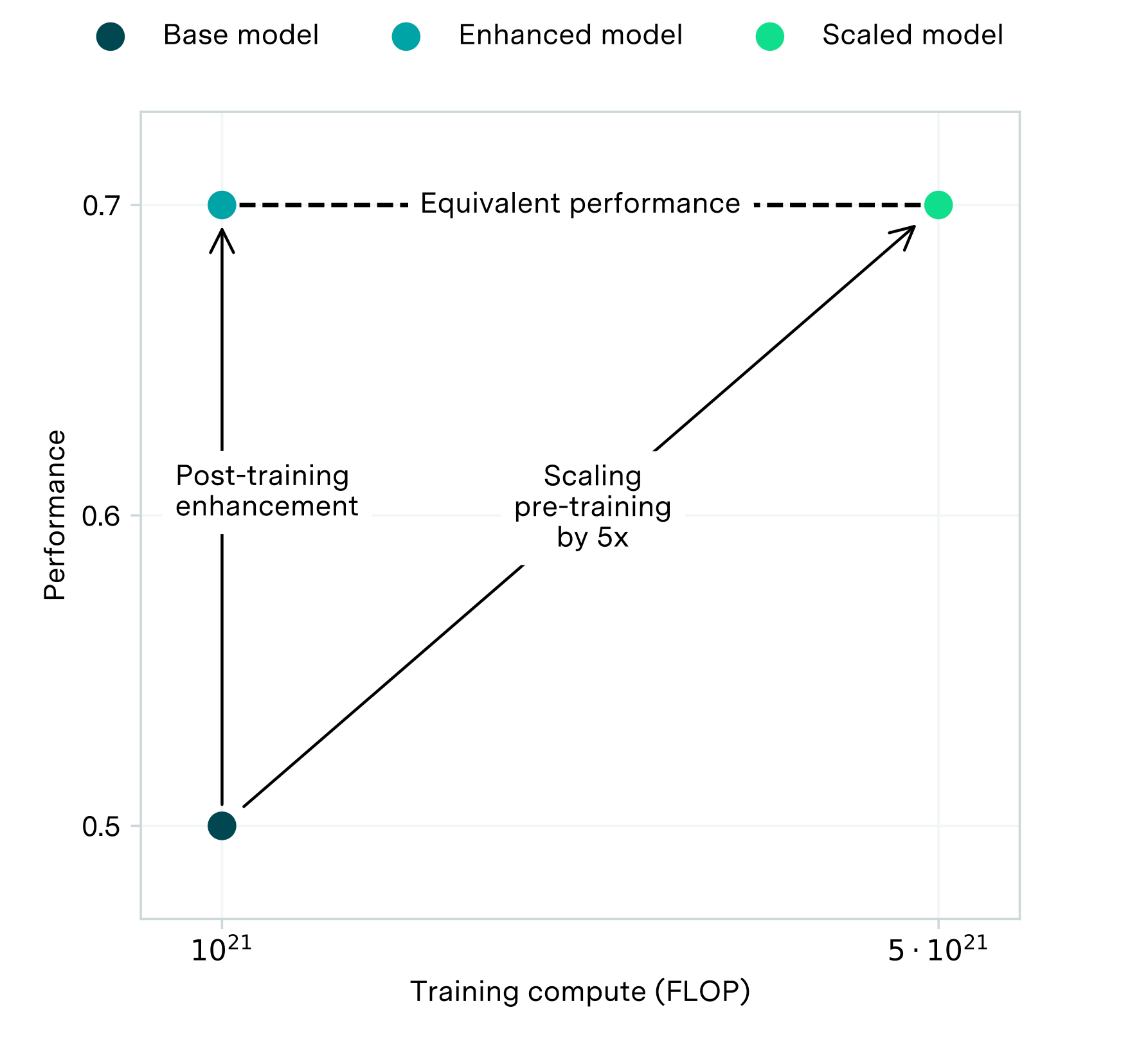
AI capabilities can be significantly improved without expensive retraining.
So, while exciting, this development isn't unprecedented; it's another churn in the ongoing evolution of AI capabilities.
Dual Engines: Training and Inference
Pre-training compute and model size remain crucial. Both inference and training compute are important and complementary. We can simplify this relationship as:
Performance = ComputeTraining × AlgorithmicEfficiencyTraining × ComputeInference × AlgorithmicEfficiencyInference
This means that those with the best insights—optimal algorithms for pre-training (AlgorithmicEfficiencyTraining) and the most effective ways to translate inference compute to capabilities (AlgorithmicEfficiencyInference)—can extract the best capabilities. It also means that even with a smaller model (hence smaller training compute), these new insights into reasoning techniques and increased inference compute can now achieve previously unattained AI capabilities.
Consequently, some actors might extract even more performance due to new algorithmic insights—be it training insights (e.g., training data selection) or post-training enhancements (as demonstrated by GPT-o1). This effect isn't new: actors catching up and achieving higher capabilities with smaller models is known as the "access effect." Simultaneously, actors at the frontier benefit from the "performance effect."
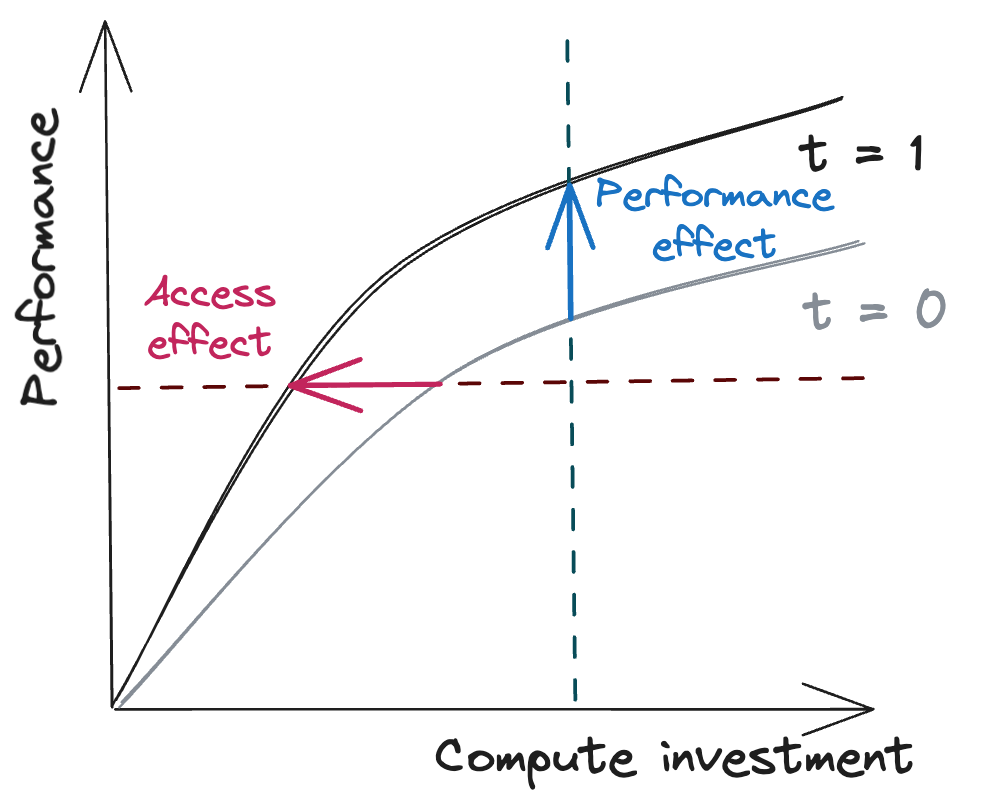
From our paper “What Increasing Compute Efficiency Means for the Proliferation of Dangerous Capabilities”
For the access effect to matter, we would need to see the technique that OpenAI employed diffuse to more actors, which is currently not the case. We lack detailed information on how it works. Assuming an actor has access to all available information and techniques, they would be able to extract the maximum capabilities from a given model.[1]
These advancements in inference don't diminish the importance of capabilities developed during pre-training. In fact, certain post-training enhancements work better with larger models, suggesting their effectiveness may depend on leveraging the capabilities of models with significant pre-training compute.
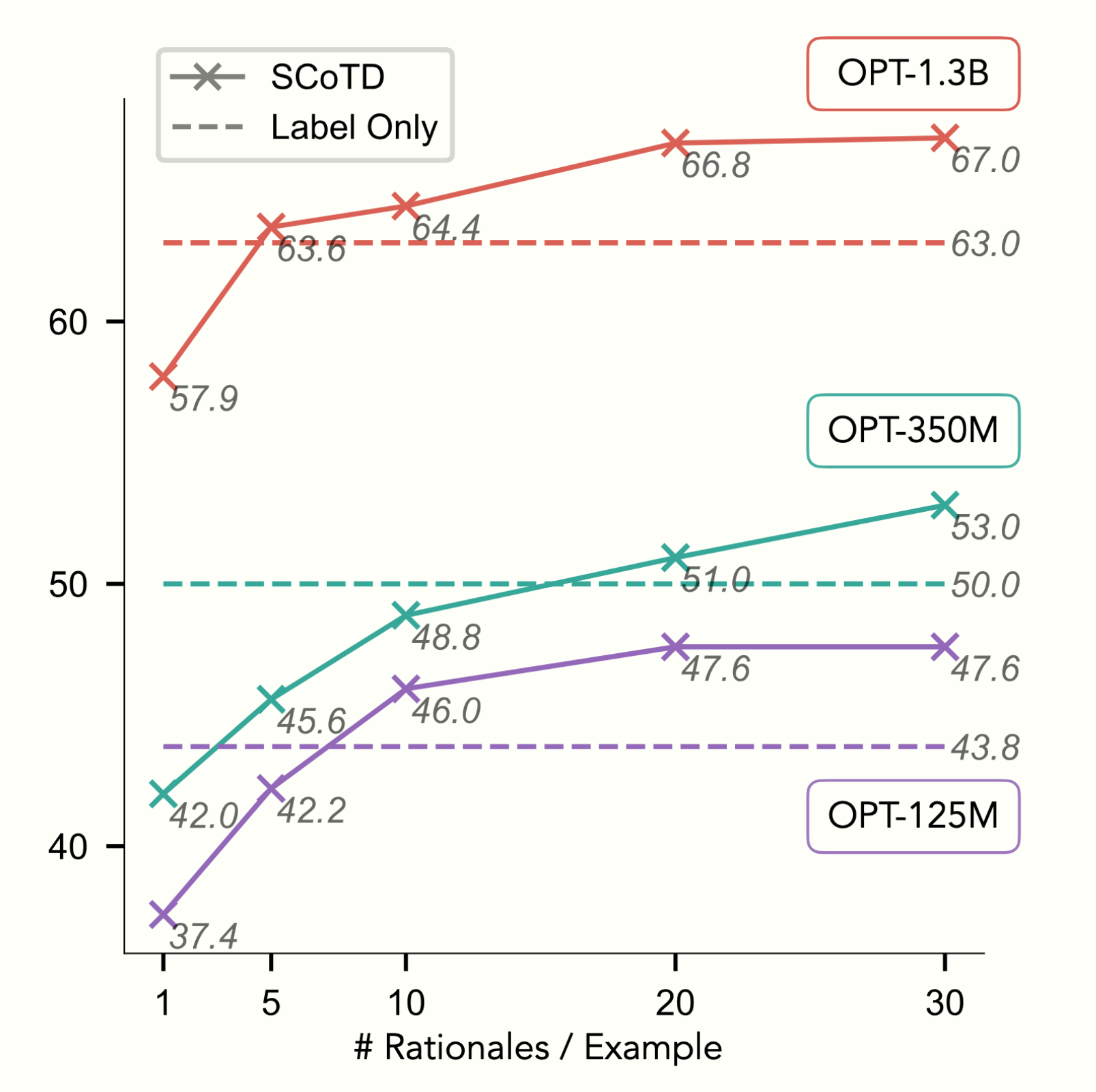
Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step
Inference & AI Governance
What are the implications of inference for AI governance? Many operate under the principle that using compute as an instrument for AI governance mostly relies on large pre-training compute. I think this is mistaken. We discuss at length here which factors bolster the case for compute as a tool for AI governance, and I discuss here the crucial considerations, with training being only one of them.
As mentioned earlier, the importance of inference compute is not a new concept. We have discussed the importance and policy ideas previously in several papers:
-
In the paper "Deployment Correction" (p.43), they discussed the idea of deployment oversight (based on a previous draft of mine). Notably, we argued that large-scale deployment might matter and is relevant for impact.
-
In "Computing Power and the Governance of AI," we stated:
-
Nevertheless, compute governance can still play an important role in detecting which individual actors have and/or use the largest inference capacities, which may correlate with various risks and opportunities, [...].
-
[...] Instead, for models in high demand, inference requires thousands of AI chips housed in specialized data centers to adequately serve the needs of thousands of users. The wider the deployment of AI systems (which requires more compute), the more impact they will likely have (both beneficial and harmful).However, there are many caveats to this correlation. The impact could vary significantly based on the application domain and other factors. Some inferences, or even certain users, could pose considerably higher risks than others. Hence, the relationship between deployment compute and the impact of AI systems is not as clear-cut as that observed in the context of training compute and AI capabilities.
-
-
Also, in "Governing Through the Cloud", we discuss deployment:
-
On the deployment side, which does not currently fall under the purview of the AI Executive Order, factors like the use of customer data (e.g., voice or images), the scale of deployment, the level of access to the outside world (e.g., via the internet or physical effectors), and the ability to act with limited direct supervision could be used to set a range of regulatory thresholds (Shavit et al., 2023). Developing more nuanced thresholds, beyond blunt compute capacity and usage, will require further research and collaboration between government, compute providers, AI developers, and broader civil Society.
-
-
In the Appendix, I also attach an old draft from June 2023 on an idea that I called "Deployment Oversight."
These examples highlight the importance of inference compute primarily in terms of deployment scale as a meaningful indicator for impact and, consequently, for policy.
Inference Impacts
We've established that deployment/inference compute matters significantly. Larger models, which are generally more powerful, require more deployment compute. This determines the number of model instances you can deploy, the tokens per second you can generate, and consequently, the users you can serve. While the specific impact and potential harm are less clear and complex to determine, here are some illustrative examples where the scale of compute matters:
- AI Worker Scaling: The number of AI workers is likely linearly related to available inference compute. More inference compute directly translates to more AI instances that can be deployed simultaneously, operating 24/7 across various tasks. This scaling could have profound implications for workforce dynamics and economic impacts.
- Surveillance State at Scale: AI-based surveillance and censorship could shift towards increasingly powerful LLMs and multimodal systems in the future to enhance internet censorship and advance surveillance. The scale and pervasiveness of these efforts (i.e., the number of people who can be surveilled) will depend primarily on the available inference compute and its cost. This becomes the limiting factor in determining the intrusiveness and how many people can be surveilled.
- AI Export and Soft Power: Inference compute determines user capacity. Countries with substantial inference compute could "dump" AI services, flooding international markets with cheap, state-subsidized model access. This mirrors historical patterns of exporting surveillance technologies and infrastructure to build soft power.
- Economic Relevance: Inference costs and availability are key inputs to the AI development cycle. They significantly influence AI development economics, with access to low-cost, high-performance inference compute potentially increasing revenue throughout the AI ecosystem, which could be reinvested in training more capable systems.
Challenges to Training Compute Thresholds?
While GPT-o1 doesn't fundamentally challenge current governance approaches, it does complicate the picture. This isn't surprising; a simplistic view focused solely on pre-training compute is inadequate.
Does this development challenge training compute thresholds? To some degree, but we anticipated this. The option to extract more capabilities from a model with the same training compute already existed. While this highlights the need for ongoing monitoring and potential revisions, I believe that current uses of compute thresholds remain valid (often, criticisms stem from misunderstanding what training compute thresholds aim to achieve and how they're used).
One might argue that we now need to measure inference compute and reinforcement learning compute. However, this isn't the correct conclusion; not all FLOP translate equally to capabilities. We know that training smaller models on carefully selected data can lead to enhanced capabilities (though this may matter less for large models that need to utilize most available data). We also know that small amounts of fine-tuning can significantly enhance performance on specific benchmarks—but this doesn't necessarily improve general performance. Ultimately, we care about how compute translates to general capabilities, and we have some established theories for pre-training compute. The picture is more complex for post-training enhancements, where compute utilization translates differently into capabilities, we lack established scaling laws, and sometimes the resulting capabilities aren't general. I expect this complexity to increase.
In my recent paper on training compute thresholds, I argue that the compute threshold should be based on the capabilities of enhanced systems like GPT-o1, rather than solely on the pre-trained model's capabilities. However, you would use the pre-training compute of the underlying model as the metric. This approach accounts for the capabilities that models will ultimately achieve. Additionally, one could add a safety buffer to account for potential future improvements in post-training enhancements. GPT-o1 raises questions about the size of this safety buffer, which would require more details to analyze.[2]
Blurring Line Between Training and Inference
Another key lesson is that the line between training and inference is blurring. Inference can be critical for producing synthetic data, which might have been leveraged for GPT-o1. This is particularly important given that the "natural" supply of human-generated data may be insufficient for increasingly large frontier training runs in the coming years. Additionally, advanced AI systems may be trained in part through "self-play," a process where AIs improve by interacting with each other (as demonstrated by AlphaZero). This "training" paradigm requires heavy usage of inference compute, further blurring the distinction between training and inference.
Compute-Intensive Inference as a Defensive Asset
The compute-dependent nature of these advanced inference-time capabilities may actually provide an advantage for well-resourced actors in defending against misuse by less well-resourced actors. We discussed this in our paper "Increased Compute Efficiency and the Diffusion of AI Capabilities":
One way to mitigate risks from the proliferation of dangerous capabilities is to invest in defensive measures. In particular, large compute investors may be able to use their ongoing performance advantage to detect and address threats posed by irresponsible or malicious actors. For instance, large compute investors may offer cybersecurity tools for automatic threat detection and response that defend against attacks by less capable models developed by rogue actors. Similarly, automated detection of disinformation could limit the impact of AI on epistemic security. Even as a model approaches a performance ceiling, large compute investors may be able to provide effective defensive measures by leveraging their superior quantity of inference compute (e.g., by deploying more and/or faster model instances).
Unresolved Questions
The development of GPT-o1 raises important questions about transparency and access to technical insights:
- Should the chain-of-thought process be hidden from users? OpenAI has chosen to show only a summary, citing reasons including user experience, the potential for future monitoring, and alignment (since they don't “safety tune” the reasoning).[3]
- What are the implications for model evaluation and oversight? At the very least, evaluators should have access to the full chain of thought.
- Does this impact the value of model weights theft? Algorithmic insights are not constrained to only getting baked into the weights. They can also be part of the inference and scaffolding setup. This makes stealing potentially less valuable (but still a significant concern).
- What does this mean for the compute requirements of stolen weights? It may be harder to steal effectively because you need more compute to squeeze out the full capabilities. Generally I think many underestimate how often you would need to deploy a model at scale (and the resulting massive compute infrastructure requirements) for certain types of harm (but not for all of them).
- How does the reinforcement learning on reasoning work? Is it using mostly synthetic data? How much compute was utilizied? This would further impact the importance of inference compute and feed into the whole development costs.
- To which degree should we expect larger models to have better reasoning capabilities? A lot of the model weights are being used to memorize facts. Can small models reason as good, and we should not expect larger models to gain more from post-training enhancements?
These questions highlight the increasing challenge of my role in focusing on the technical aspects of AI governance. I have many open technical questions which should inform my governance and policy research. As an outsider in the non-profit world, it's becoming more challenging to make informed decisions without full access to technical details. How can researchers get more access to detailed information? Transparency might be beneficial but it comes at a cost. Alternatively, one might need to transition into government roles where they hopefully soon have insights into these types of data or can request it.
Thanks to all for the insightful discussions on this topic. All views expressed here are my own and, as always, subject to change as new information comes in.
For example, we have limited technical insights into how GPT-o1 (Strawberry) works. Many assume that algorithmic efficiency improvements are distributed equally—I believe this era ended some time ago. Algorithmic efficiency improvements are often distributed unequally. Frontier AI developers are increasingly reluctant to publish advances, given their relevance to competitive advantage and potential misuse. For example, in 2019, OpenAI published details on the architecture, data, and algorithms used for GPT-2, whereas in 2023, GPT-4's publication included almost no such information. As a result, algorithmic advances are increasingly concentrated at frontier AI developers, diffusing only through leaks, parallel innovation, or employee transitions. For more discussion, see Pilz et al., 2023. ↩︎
The challenge here is that not all actors can extract the same capabilities from a given model. Should we assume every actor can match OpenAI's capability extraction? Currently, they can't, due to lack of insights and different fine-tuning approaches. But theoretically, they could (e.g., we might see an enhanced version of LLama that achieves this). ↩︎
OpenAI’s blog post says: "We believe that a hidden chain of thought presents a unique opportunity for monitoring models. Assuming it is faithful and legible, the hidden chain of thought allows us to "read the mind" of the model and understand its thought process. For example, in the future we may wish to monitor the chain of thought for signs of manipulating the user. However, for this to work the model must have freedom to express its thoughts in unaltered form, so we cannot train any policy compliance or user preferences onto the chain of thought. We also do not want to make an unaligned chain of thought directly visible to users. [...] Therefore, after weighing multiple factors including user experience, competitive advantage, and the option to pursue the chain of thought monitoring, we have decided not to show the raw chains of thought to users. We acknowledge this decision has disadvantages. We strive to partially make up for it by teaching the model to reproduce any useful ideas from the chain of thought in the answer. For the o1 model series we show a model-generated summary of the chain of thought." ↩︎
Appendix: Deployment Governance
This is an old draft from June 2023. Some of this ideas got folded into “Computing Power and the Governance of AI”, “Governing Through the Cloud,” and “Deployment Corrections.”
While there is a compelling case for leveraging the governance capacity of compute prior to AI training, it can also be exercised during deployment. The majority of all AI compute resources are used during AI deployment, i.e., inference.
All things equal, more available compute translates to more inferences, which in turn could lead to a greater impact, and potentially greater harm. For example, a chatbot used by 100 million users compared to 1 million users necessitates 100 times the compute and potentially carries 100 times the impact. Additionally, larger models — those with more parameters — also require more linearly more compute with their size for the inference. Thus, to some extent the relationship between compute and impact observed in training also extends to deployment.[1]
Given the reduced and diverse compute requirements during inference, it’s not feasible to regulate every instance of inference. However, we argue that the majority of all AI deployments, particularly those at scale, occur on large compute clusters similar to those used for AI training owned by cloud compute providers. This implies that these deployments could also be subject to oversight, and the governance capacities of compute can be mobilized. We refer to this as “deployment oversight.” This could involve not just using compute as a governance node for knowledge and enforcement to detect harmful deployments, but also to enforce their shutdown.
Deployment oversight could enhance the liability and enable a more effective incident response—offering a mechanism for post-incident attribution. In the event of an AI incident, it is important to understand how it occurred, and stop more harm from occurring. In particular, we think it is beneficial to:
- (a) Have the capability to immediately shut down the AI system, preventing additional harm. The sooner an intervention occurs, the more harm is prevented.
- (b) Identify who deployed the model. Cloud providers could trace model outputs and actions back to the originator. Techniques such as watermarks or signatures on the model’s output could help.
- (c) Understand the model’s origin. Questions such as whether the model is a derivative of another, who the original model creator is, whether the model has been stolen, and who is liable, are of importance.
Governance practices similar to this are common. For example, the hosts of malicious websites, such as ones where illegal drugs are sold, often remain anonymous, and the only available governance intervention is to shut down the servers hosting these websites. Government access and close contact with the host—similar to the role of the compute provider we are discussing here—can be advantageous to act promptly.
Moreover, we anticipate that the majority of all inference compute could be regulated and governed as it is being hosted in a small amount of data centers housing a large number of AI chips (Pilz & Heim, 2023) — similar to the infrastructure being used for training AI systems. Consequently, the larger portion of inference compute could potentially be employed as a defensive mechanism against ungoverned compute, whether orchestrated by humans or runaway AI systems. This might lead to a state of "inference dominance" wherein the capacity to deploy multiple model copies, and more inferences, for defense considerably outweighs offensive applications. Should potential powerful models that can be misused become widely accessible, e.g., via having compute requirements that allow the deployment on personal devices, a government could ensure that the vast majority of inference is focused on misuse mitigation.[2] Eventually, this depends on the offense-defense balance of future AI systems (Garfinkel & Dafoe, 2019).
Lastly, it is in the interest of compute providers to ensure their infrastructure is used safely and that the models deployed meet certain security standards. Compute providers should also be interested in reducing their liability by following security practices and mitigating the misuse of their compute resources—transferring the liability to the deployer and/or the foundational model provider.
However, there are many caveats to this correlation. The impact could vary significantly based on the application domain and other factors. Some inferences, or even certain users, could pose considerably higher risks than others. Hence, the relationship between deployment compute and the impact of AI systems isn't as clear-cut as that observed in the context of training compute and AI capabilities. ↩︎
We might even envision a scenario where the government reserves the right to allocate compute for defensive purposes. ↩︎