Crucial Considerations for Compute Governance
Compute plays a significant role in AI development and deployment. However, many arguments contest its importance, suggesting that the governance capacity that compute enables can change.

Compute plays a significant role in AI development and deployment. However, many arguments contest its importance, suggesting that the governance capacity that compute enables can change. I differentiate between factors that (i) impact the governability of compute itself and those that (ii) reduce the importance of compute for AI systems.
Not every point raised here undermines all proposals that leverage compute,[1] as these proposals differ depending on the discussed factors. More importantly, I recommend treating this list as a "checklist" when deliberating a new AI governance intervention. By doing so, stakeholders can identify which of these considerations are important to monitor and factor into their specific governance proposal.
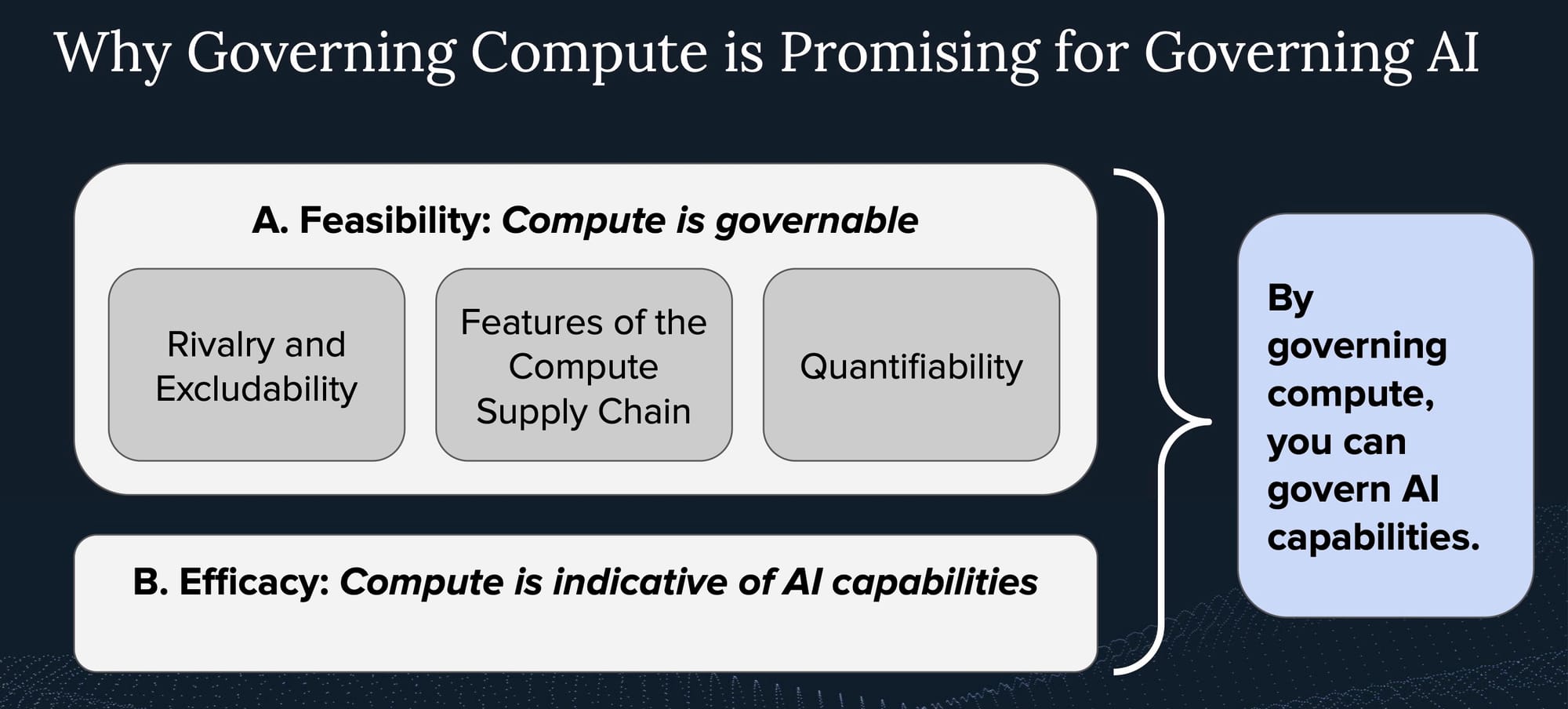
Figure 1: Why Governing Compute is Promising for Governing AI.
Challenges to the Governability of Compute
-
Uncertainty of computing performance progress and paradigm: If the advancement of computing performance stagnates, for example, if Moore’s Law slows, then multiple effects would likely follow.
- It could prevent the decrease of costs for developing and deploying AI systems, potentially leading to decreased training compute scaling.
- Second, more actors might gain the ability to produce cutting-edge chips over time, potentially reducing supply chain concentration and flattening or increasing access.[2]
- Concurrently, less frequent AI chip replacements might follow, posing challenges to strategies like monitoring chip supply or implementing new governance mechanisms on the latest hardware. Presently, the exponential improvement in AI chips’ performance creates an incentive for continuous upgrades; new hardware generations swiftly outpace their predecessors, capturing a large share of the total aggregated computational performance available worldwide. If this trend halts, the demand for the latest chips may wane, diminishing the effectiveness of governance approaches that depend on the adoption of new chip generations or supply chain tracking.
-
Identifying the regulatory target: While the discussion often focuses on data-center AI chips, some limitations exist. It is important to recognize that AI is not inherently limited to these hardware architectures, and the landscape of AI hardware will continually evolve in response to technological advancements, regulatory constraints, and the changing needs of AI applications. For example, gaming GPUs could be leveraged for training models, or instead of centralized, concentrated AI compute clusters, decentralized training[3] could also be feasible. While there would indeed be a performance penalty for doing so, this may not be significant enough to deter a motivated actor. Targeting all the compute worldwide is neither feasible nor desirable. Such an approach would inevitably impact the majority of compute which is not of relevance for frontier AI activities, and would represent a significant invasion of privacy while also being overly blunt in its implementation.
-
Digital accessibility of compute: Restricting physical access to chips doesn’t necessarily restrict digital access to the compute they provide. Compute can be accessed via digital means (“Infrastructure as a Service” (IaaS) or “cloud compute”), independent of location and jurisdiction. Alongside controlling physical access to chips, monitoring digital access—such as the customers of cloud providers—is warranted. However, governing digital access might offer benefits. Unlike the strategy of limiting access to AI chip purchases, regulating the digital access to compute offers more precise controls, allowing regulatory control over compute quantities, as well as the flexibility to suspend access at any time.[4]
-
Changes in the compute production, e.g., the semiconductor supply chain: An increasing number of actors, or countries developing their own supply chain, would reduce current governance capacity, i.e. losing control over chokepoints. For example, China having cutting-edge chip production capabilities would undermine current existing AI chip export controls. In addition, the emergence of new technologies or computing paradigms could reduce reliance on the current supply chain, which is characterized by strong concentration and control by certain nations.[5]
-
Non-robustness and slow roll-out of hardware-enabled mechanisms: Implementing mechanisms on AI chips and infrastructure ("hardware-enabled mechanisms") is a complex and time-consuming process. First, it might not be robust to tampering, and secondly, waiting for new hardware generations that include the desired mechanism can take considerable time. Retrofitting might not always be feasible.[6]
-
International cooperation requirements: While the semiconductor supply chain is currently concentrated, largely under the control of the U.S. and its allies, all nations have a need for semiconductor products. International cooperation is crucial for effective governance but may prove challenging due to diverse interests and priorities.
Limitations in Compute's Contribution to AI Capabilities
-
AI domain-specific compute needs: Not all AI applications require vast amounts of compute. For example, certain applications like AlphaFold achieve significant functionality without extensive compute resources. One estimate claims that AlphaFold used just 0.003% of the compute used to train PaLM (540B). Hence, training a system on a given compute budget might lead to an ultrahuman protein folding AI system but only an okay LLM. When considering general-purpose systems trained on similar datasets, compute serves as a fairly accurate proxy for capabilities, allowing for a hierarchy of system "concerningness" based on compute levels. However, when specifically aiming to train specialized systems for potentially hazardous tasks, it's feasible to achieve these tasks using far less compute than what would be necessary for training a general system to a comparable capability level. With this in mind, other metrics should also be evaluated, and one might need to adapt compute indices depending on the application area and domain.[7]
-
Increased compute efficiency - reduced compute requirements over time: If systems with certain capabilities become trainable on less powerful devices due to increased algorithmic efficiency, compute would lose its leverage as a governance node. Algorithmic efficiency and hardware improvements could enable potentially dangerous systems to be trained on a wider range of devices, such as consumer devices.[8] However, based on extrapolating current trends, it might take a considerable time before we see systems with reduced compute intensity being trained outside of data center clusters. For instance, current systems, such as GPT-4, would need to reduce their compute requirement by a factor of three orders of magnitude to be trainable on a single consumer GPU. See “Increased Compute Efficiency and the Diffusion of AI Capabilities” for a longer discussion on this.
-
Limits of the compute trend: The current growth in compute spending for frontier AI systems is unsustainable, as it outpaces the decline in compute costs. As this spending encounters natural limits, such as a significant portion of a country’s GDP[9], the growth trend in training compute usage eventually plateaus. The date will be determined by both the cost of compute and the limits of how much stakeholders are willing to invest, predominantly driven by the capabilities of the AI systems and their return on investment. Upon reaching this stage, other inputs might gain more relative importance, or AI progress might hit a plateau. Also, reaching this saturation might shift the governance focus. Instead of anticipating and managing ever-larger training runs, the emphasis could change towards preventing the proliferation of existing high-level systems.
This section was initially written as a contribution for a paper. Some of the content is included in Sastry, Heim, Belfield, Anderjung, Brundage, Hazell, O'Keefe, Hadfield et al., 2024, Section 5.
Future iterations might include a more granular way of clustering the raised points and more directly pointing to the governance proposal that might be affected (e.g., the way in which the failure/ineffectiveness is produced).
See Sastry, Heim, Belfield, Anderjung, Brundage, Hazell, O'Keefe, Hadfield et al., 2024 for a list of risk-reducing policies that leverage compute. ↩︎
See Section 3.B.4 of Sastry, Heim, Belfield, Anderjung, Brundage, Hazell, O'Keefe, Hadfield et al., 2024. ↩︎
Decentralized training describes the training of ML systems across (clusters of) AI accelerators that are not concentrated at a single location. This is a spectrum from centralized, e.g., a single datacenter, to extremely decentralized, e.g., distributed AI accelerators across many homes. The key determinant is the reduced communication bandwidth between (some of) the accelerators/nodes due to being decentralized and hence being interconnected via different mediums and protocols. ↩︎
Monitoring and managing digital access to compute could, in fact, be more favorable. Compared to physical access, digital access offers more granular control and monitoring possibilities. Access can be restricted at any time and for specific durations. In addition, the digital allocation of compute can be measured in terms of “chip-hours,” reflecting the actual use of compute resources. This provides an upper limit for the available computing power that can be utilized for development or deployment, thereby enabling more precise governance of AI applications. ↩︎
However, dramatic shifts seem rather unlikely in the short term. Most hybrid approaches still depend on the semiconductor supply chain, and new computing paradigms may not initially be cost-competitive but could become so over time. ↩︎
Consequently, exploring earlier versions of these desired mechanisms through firmware or software updates might be necessary. However, hardware-enabled mechanisms are later favorable to protect against adversarial actors and enhance security. ↩︎
Predicting the downstream impacts of AI systems or research contributions can be challenging, as AI tools developed for one purpose can often be repurposed for others. For example, an AI drug discovery tool could be repurposed for designing biochemical weapons or other toxic substances. Therefore, solely considering the intended uses of a model is insufficient. ↩︎
Increasing compute efficiency, the combined phenomenon of improving hardware and algorithms, indicates that the hardware requirements to achieve a given capability decrease over time. This leads to an access effect, giving an increasing number of actors access to advanced capabilities. However, increasing compute efficiency also causes a performance effect, benefitting large compute investors by granting them acess to advanced capabilities with the same investment. While the access effect inadvertently causes dangerous capabilities to proliferate over time, the threat this proliferation poses depends on the offense-defense balance of future AI systems. In some cases, leaders may be able to use their compute advantage to train higher-performing systems ans run them at scale to counter malicious use by weaker systems. See Pilz et al., 2023. ↩︎
Heim (2023), based on an updated model developed by Lohn & Musser (2022) that naively extrapolates the current trends in training compute and the reduced cost of compute over time, estimates suggest that by around the year 2032, the total cost of training a state-of-the-art AI system would equate to approximately 2.2% of the U.S. GDP, similar to the annual cost of running the Apollo project. ↩︎