Measuring what Really Matters: Optimizing Neural Networks for TinyML
This work addresses the challenges of bringing Machine Learning to microcontroller units (MCUs), where we focus on the ubiquitous ARM Cortex-M architecture.

Unfortunately, there are some formatting mistakes, as there's no straightforward way to export LaTeX to Markdown without formatting errors. Please refer to the arXiv:2104.10645.
Please cite as
@article{DBLP:journals/corr/abs-2104-10645,
author = {Lennart Heim and
Andreas Biri and
Zhongnan Qu and
Lothar Thiele},
title = {Measuring what Really Matters: Optimizing Neural Networks for TinyML},
journal = {CoRR},
volume = {abs/2104.10645},
year = {2021},
url = {https://arxiv.org/abs/2104.10645},
archivePrefix = {arXiv},
eprint = {2104.10645},
timestamp = {Tue, 27 Apr 2021 14:34:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2104-10645.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Measuring what Really Matters: Optimizing Neural Networks for TinyML
- Lennart Heim, ETH Zürich and RWTH Aachen
- Andreas Biri, ETH Zürich
- Zhongnan Qu, ETH Zürich
- Lothar Thiele, ETH Zürich
Abstract
With the surge of inexpensive computational and memory resources, neural networks (NNs) have experienced an unprecedented growth in architectural and computational complexity. Introducing NNs to resource-constrained devices enables cost-efficient deployments, widespread availability, and the preservation of sensitive data.
This work addresses the challenges of bringing Machine Learning to microcontroller units (MCUs), where we focus on the ubiquitous ARM Cortex-M architecture. The detailed effects and trade-offs that optimization methods, software frameworks, and MCU hardware architecture have on key performance metrics such as inference latency and energy consumption have not been previously studied in depth for state-of-the-art frameworks such as TensorFlow Lite Micro. We find that empirical investigations which measure the perceptible metrics –performance as experienced by the user– are indispensable, as the impact of specialized instructions and layer types can be subtle. To this end, we propose an implementation-aware design as a cost-effective method for verification and benchmarking. Employing our developed toolchain, we demonstrate how existing NN deployments on resource-constrained devices can be improved by systematically optimizing NNs to their targeted application scenario.
1. Introduction
The popularity of the Internet of Things (IoT) has resulted in a plethora of applications demanding intelligence “at the edge”, ranging from human pose recognition [25] and crowd surveillance [53] to natural hazard monitoring [37]. However, current state-of-the-art NNs often make significant demands on memory, computation, and energy [38, 39, 45]. This contradicts the resource-constrained nature of IoT devices which only provide a low-power MCU. In TinyML, researchers attempt to bring NNs to these edge devices by exploring more efficient models using neural architecture search (NAS) [9, 32] and compressing pretrained NNs for efficient on-device inference through pruning [14, 16], quantization [24, 33, 40], or distillation [19].
For efficient inference, research has focused on minimizing metrics such as the memory footprint of the network as well as the number of multiply accumulate (MACC) operations and floating point operations (FLOPs) while maintaining an acceptable accuracy. For this optimization, the latter serve as proxies for the computational complexity, as they can be easily determined analytically based on the network architecture, even before the computationally intensive training [5, 32]. Especially for MCUs and other CPU architectures, it has been claimed that MACC operations provide a better proxy than for co-processors like GPUs due to their simpler hardware architecture [5, 32]. Nonetheless, those metrics are only proxies for the metrics the user is exposed to: the inference latency and energy consumption – what we call perceptible metrics. While commonly used for the final assessment of a network’s efficiency, our experimental results show that these proxies do not always correctly reflect the final runtime metrics, resulting in misleading conclusions and suboptimal automated search strategies. However, most current designs still substitute selection requirements with these proxy metrics and do not take perceptible metrics into consideration. In addition, they do not exploit architectural MCU features that heavily influence the reliability of such metrics, thereby missing the opportunity for a symbiotic hardware-aware NN design.
In this work, we analytically and experimentally investigate the implications of perceptible metrics for NN design. We examine their correlation to other common metrics and propose concrete design guidelines for future networks targeted at edge devices. To the best of our knowledge, we are the first to take such empirical metrics directly into account and facilitate the targeted selection of suitable NNs for application-specific scenarios.
While the hardware architecture of MCUs is less complex than desktop-class CPUs and co-processors such as GPUs or tensor processing units (TPUs) [27], their computational and memory resources are inherently limited. Therefore, achieving an efficient NN execution by leveraging architectural features is paramount. Given the simplified underlying architecture (flat memory hierarchies, few to no caches, and shallow pipelines), we can analytically understand its implications and exploit it more effectively. Focusing current efforts of Machine Learning (ML) on the edge solely on co-processors would render many of the existing systems and even more upcoming ones unsuitable. The deployment on already available MCU architectures can enable on-device inference today on billions of commercial devices. We demonstrate this by deriving design guidelines based on an analysis of the ubiquitous ARM Cortex-M [3] architecture, used in 4.4 billion MCUs sold in the last quarter of 2020 alone [2].
In particular, we make the following key contributions:
- We present a complete hardware and software toolchain that enables the implementation-aware investigation of key performance metrics such as inference latency and energy consumption. It includes portable benchmarking tools to quantify, analyze and optimize NNs at layer granularity by deploying them directly on MCUs – shown in Section 3.
- We demonstrate that experimental investigations are indispensable, as estimating energy efficiency and inference latency analytically is prone to anomalies. The combination of optimizations leads to a non-uniform acceleration across the NN, whose layers display an intricate interplay that is difficult to quantify without empirical validation – which we focus on in Section 4.
- We show that the use of proxy metrics such as operations can be misleading and neglects actual hardware utilization. Leveraging architectural insights and using implementation-aware metrics while designing NNs permits us to fine-tune networks. This allows us to increase their computational complexity and hence potential for higher accuracy [38] while simultaneously reducing latency and energy consumption by following simple guidelines, as presented in Section 5.
2. Related work
Various research efforts have targeted NNs on resource constrained devices. We group existing work into network compression, efficient architecture design, and NAS.
Compression Quantization reduces the bit-width of NN parameters, which permits a drastic reduction of the memory footprint [24, 33, 40]. It has become a standard compression technique in TinyML due to its significant memory savings while usually having a negligible effect on accuracy [11]. Whereas quantization can in principle be used with any bit-width, e.g. 4 bit [7] or an adaptive bitwidth [40], we focus on 8 bit quantization which is supported by most MCUs. Unsupported bit-widths need to be emulated, resulting in inefficient hardware utilization [3, 5].
While weight sharing [10, 14] and network pruning [14, 16,56] have shown promising results for efficient inference, their usage on edge devices remains an open challenge as they are not yet supported by open-source frameworks.
Efficient architectures An efficient base architecture for further pre-deployment optimizations can either be designed manually or systematically searched for. With the rise of NNs on phones, novel architectures such as MobileNets [21], SqueezeNet [23], SparseNet [36], ShuffleNet [55], and EfficientNet [31, 48] have been proposed. Those NNs highlight a new trend aside from primarily focusing on the accuracy, as they also consider network complexity – the interplay between accuracy, number of parameters, activations, and operations. However, their applicability to TinyML is limited, as the resources on such systems are far more constrained than for mobile phones.
Neural architecture search Instead of manually designing networks, NAS finds such efficient architectures in an automated manner by systematically exploring the design space using a set of selected evaluation criteria. A NAS system can be split into three components: the search algorithm, search space, and evaluation strategy [12]. Whereas search algorithms can be partially reused from existing work, the search space has to be redesigned and drastically reduced due to the limited memory. The evaluation strategy also requires adjustments to take the specific application requirements and concrete hardware constraints into account.
Furthermore, as many TinyML systems are user-facing IoT devices, it is oftentimes required to optimize for multiple metrics at the same time. Perceptible metrics, such as latency and energy consumption, are subject to specification requirements and often more expressive and constrained than accuracy. Therefore, multi-objective optimization became more prominent and has been incorporated into the evaluation strategy [12, 22]. However, while acknowledging the importance of perceptible metrics, these NAS designs use proxies like operations after having verified a linear relationship between them [5, 32]. In contrast, the use of latency lookup tables [52] based on previously measured executions directly integrates perceptible metrics.
Based on the evaluation strategy, we can divide NAS approaches into four categories: no hardware influence [35], the usage of proxies characterized in advance [5, 9, 32, 34], hardware-aware measurement and usage of perceptible metrics [52], and hardware/software co-design [54]. While hardware-aware NAS has primarily targeted co-processors [1, 27] (more than 75 % of published papers [8]), we argue that CPU architectures are a worthwhile target due to their ubiquitous availability in existing, deployed systems. Our work investigates the perceptible metrics of this device class and evaluates the applicability of proxies through experiments to showcase its true potential.
3. Method
In contrast to previous work which relied on proxy metrics, we focus on perceptible metrics which characterize the system as experienced by the user. Therefore, they are the center of our designed methodology and resulting toolchain.
3.1. Bridging theory and implementation
By focusing on the number of operations as an optimization target, many details are lost in translation [29] and theoretical operation cost estimates do not necessarily match the atomic instructions of the hardware architecture which are eventually executed. First, operating on floating point or on fixed point is a significant difference, especially when the underlying hardware does not natively support it (i.e. no FPU is available). On top of this, the chosen bit-width is a key factor, as smaller bit-widths can be leveraged by larger bit-width architectures through aligned memory access and the usage of supported single instruction multiple data (SIMD) instructions. Aside from the quantization, the operation type is equally important. While a MACC operation contains one multiplication and accumulation per cycle, FLOPs only execute a single computation. However, the exact conversion depends on the extent to which the underlying layer can exploit parallelization and is hence strongly implementation dependent. Consequently, if 8 bit quantization is used on a 32 bit hardware architecture, an acceleration of up to 4× is expected if aligned memory access and SIMD can be leveraged. However, the limited number of registers in MCUs and the NN structure can limit this exploitation, as we will discuss in Section 4.
Taking these differences into account is intricate for complex architectures such as CPUs, GPUs, or TPUs [27]. Nonetheless, we find that the comparatively simple architecture of MCUs, in particular the shallow memory hierarchy and the predominantly serial computation, permits us to analyze and exploit it both analytically and experimentally.
To investigate the potential for exploitation, an empirical evaluation of the latency per MACC operation enables an expressive comparison of different NNs, their layers, and target hardware. In particular, the influence of optimizations on this perceptible metric demonstrates the variable
comparative cost of individual layers. By calculating the
number of operations for the layers of a NN and measuring
the inference latency, we can compute the resulting latency
per operation for different layers and their hyper-parameters
with δ = tm . tm represents the measured inference latency ce
and ce is an estimate for the required MACC operations of the NN layer (see Appendix A for the derivation). As we disregard load and stores operations, this equation defines a upper bound on the actual execution latency. However, we can extract knowledge on the relative efficiency of layer types themselves as well as the hyper-parameters’ influence by comparing layers and different hyper-parameters [26], which we will demonstrate in Section 4.

3.2. Implementation-aware toolchain
Following established guidelines [6], our methodology allows us to gather first insights on the inference latency and energy consumption. In addition to these perceptible metrics, we provide traditional metrics [46, 47] to evaluate and design an architecture: accuracy, NN size and computational complexity (i.e. number of operations). With this combination of metrics, we can observe the subtle impact of optimizations and investigate the correlation of standard metrics and their applicability for feedback on the architecture and optimizations under observation. For this, we build on top of proven ML methods and integrate insights from the embedded systems domain to design a toolchain that allows us to gather metrics down to layer-wise granularity.
In this subsection, we give a brief end-to-end overview of our proposed toolchain architecture, as depicted in Figure 1. It consists of the the following components: model analysis (A), optimizations (B), on-host evaluation (C), deployment (D), benchmarking and energy monitoring (E), and target evaluation (F). Whereas components A C are executed on the host system (e.g., a desktop computer which is not resource-constrained), components D F directly incorporate the targeted embedded system. Notice that while we only depict the flow of information, the design flow permits closer iterations as all of the components can be used individually to enable an efficient optimization process.
3
Model analysis (A) Starting with a previously designed and pre-trained base model that is not yet optimized for TinyML systems, the initial accuracy and loss can be easily determined. Additionally, the memory footprint of the NN (i.e. the required space for weights and biases) can be determined. Those results can then be used as a reference for the impact of the optimizations on accuracy, loss, and model size. Additionally, the model complexity can already be investigated at this stage, as the number of parameters as well as the estimated operations remain fixed.
Optimizations (B) During the model optimization stage, we optimize the model using quantization as discussed in Section 2. At this stage, all optimizations are still hardware and target-independent, as the deployment target is not yet known. However, the effect of quantization can depend on the deployment target and the supported bit-widths of the underlying MCU architecture. This can result in significant acceleration if the quantization type is chosen in synergy with the target hardware.
On-host evaluation (C) Optimizations permanently alter the NN and potentially influence its accuracy. Therefore, on-host evaluation enables us to already assess the quantized model. The host system (e.g., a desktop computer) is not resource-constrained and permits a time-efficient evaluation using the test dataset – which is usually too large to be stored directly on the resource-constrained system. There, the quantized model can be evaluated in regards to its accuracy and memory savings of the NN parameters compared to the base model. As some models might suffer a more substantial accuracy loss than others through optimization, quantifying this dependence pre-deployment is crucial.
Target deployment (D) Depending on the targeted device, specialized optimizations are available, such as software acceleration libraries like CMSIS-NN [28], which provide the possibility to leverage dedicated, hardware optimized kernels. In contrast to the previously discussed optimizations, these do not change the numerical representation itself but increase the execution efficiency by leveraging target-specific features like SIMD instructions. During the deployment step, the already converted and optimized model and the required inference engine is compiled into the final firmware for the target processor.
Benchmarking and energy monitoring (E) The benchmarking itself occurs on the target using the previously compiled benchmarking firmware and a dedicated energy measurement unit. This benchmark enables us to gather the inference latency at layer resolution as well as the resulting classification of the on-device inferences. We use a customized version of the firmware to measure the inference latency via software timers and leverage standard general purpose input/output (GPIO) signaling to interface with an external energy measurement unit. As energy is a crucial contributor to deployment costs, its efficient usage plays a
significant role in embedded systems. To evaluate the energy consumption, a separate system that interfaces with and monitors the system under test is required to gather unbiased results based on known events, such as the start and stop of individual layers or the complete inference.
Target evaluation (F) Lastly, to verify the previously gathered on-host classification accuracy results and the impact of target-specific hardware optimizations, we have the option to perform verification on the target itself. As these device-dependent optimizations cannot be investigated before the deployment, the effective impact on the accuracy needs to be evaluated. To do so, we send samples of the test dataset through a serial bus to the MCU. While the optimizations do not change the NN itself, they might alter underlying computations depending on the specific implementation, potentially resulting in a different classification. Examples of this are the approximations of hyperbolic functions [28] as well as the kernel implementation of CMSISNN, as we will show in Section 4.
3.3. Implementation
For the initial design and training of the NN, we use TensorFlow (v2.2.0) [49]. The subsequent quantization is performed with TensorFlow Lite (TFL) [50]. The final target firmware is then compiled through the inference library TensorFlow Lite Micro (TFLM) [11, 51] combined with the optimization library CMSIS-NN [28] as part of an Mbed OS [4] project (v5.15.3). Mbed OS facilitates the dynamic deployment on a wide variety of targets featuring an ARM Cortex-M MCU through a well-maintained compilation toolchain and the option to extend the evaluation to a full-featured embedded OS implementation. TFLM on the other hand is target-independent and can also be used for other CPU architectures such as RISC-V.
For the external energy measurement, we employ the open-source hardware and software project RocketLogger [41]. GPIO pins indicate the start and end of an inference as well as intermediate layers and can be traced at up to 64 kHz. The device logs measurements locally and can be accessed remotely; the complete test setup is automated and does not require any manual intervention.
With this toolchain, we provide the opportunity for a time-efficient evaluation of various NNs and target devices without requiring detailed technical knowledge of the implementation on MCUs. This enables engineers to focus their efforts on designing networks and systems while still being able to test and compare their results with minimal effort. Our work, including all software and hardware components for our toolchain, is open-sourced and publicly available [18, 41]. It includes automated scripts for preparing, deploying, and analyzing NNs. The measurement results from our evaluation are available as examples [17].
4. Experiments
In this section, we first investigate the non-uniform effects of optimizations on different NNs. We then examine the relationship of the perceptible metrics (energy and latency) empirically and discuss the resulting Pareto front for our targets. Lastly, we explore the detailed effects of layers’ hyper-parameters by examining the perceptible metrics with layer granularity using artificial benchmarking NNs.
For our experiments, we select the development boards STM NUCLEO L496ZG (L4) [44], STM DISCO F496NI (F4) [42], and STM NUCLEO F767ZI (F7) [43]. Ranging from ultra-low power (L4) over balanced (F4) to high-performance MCUs (F7), these samples represent the breadth of the ARM Cortex-M series, which we target because of its low power characteristics and ubiquity in embedded devices. If not otherwise mentioned, all experiments are conducted on the L4 as the most resource-constrained device. For benchmarking, the RocketLogger [41] allows us to measure the energy consumption and trace target GPIOs for status information on the inference. In our initial tests, we investigate LeNet [30] as a representation for the most constrained NNs as well as ResNet20 [15] to demonstrate more demanding capabilities (see Appendix C for the used NN architectures).
4.1. Effects of optimizations
Leveraging our toolchain, we investigate the influence of optimizations on the perceptible metrics in an automated manner. These experiments involve all components from the initial analysis (A) for calculating the memory savings to the target evaluation (F) of the perceptible metrics.
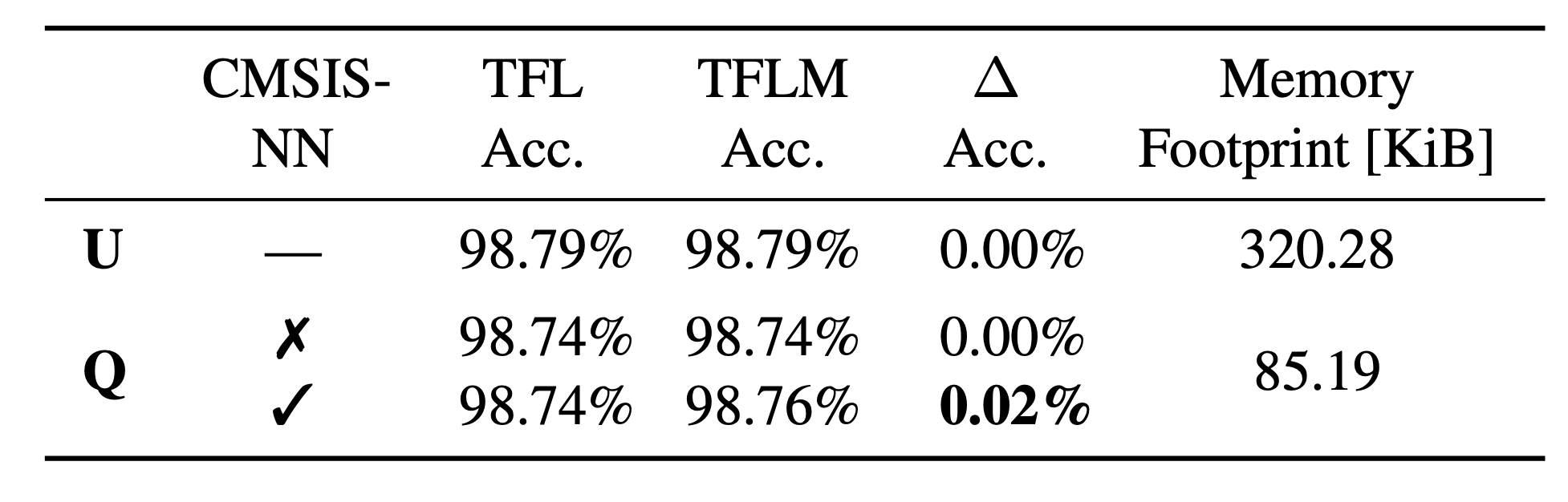
Quantization The effects of quantization can already be evaluated on the host (B) using the TFL interpreter [50]. We achieve a memory footprint reduction of up to 73 % while only losing 0.05 % of accuracy (Table 1). Consequently, when a loss in accuracy is tolerable, quantization is highly beneficial. However, this must be empirically investigated by quantizing the NN and verifying the resulting accuracy. We also evaluate the accuracy of the model on-device by
running a time-intensive verification on the MCU itself. Unexpectedly, the quantized model using CMSIS-NN displays an increased accuracy by 0.02 %. This difference in target metrics is not a feature of CMSIS-NN, but a random effect due to specific kernel implementations and a consequence of the different underlying computations [28]. For another NN, this might just as well result in a drop in accuracy.
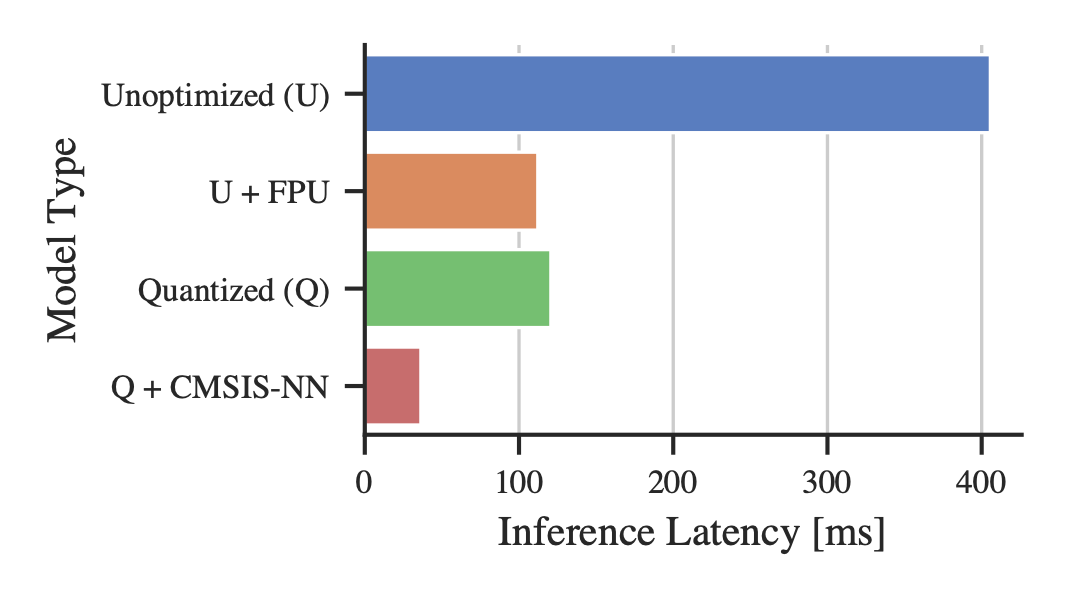
Inference latency When the floating point unit (FPU) is disabled, the unoptimized model (U) takes significantly longer – using the FPU results in a 4× faster inference (U + FPU) for the LeNet. Including the software acceleration library CMSIS-NN, we can further accelerate fixed point operations, speeding up the quantized model by an additional 4× (Q + CMSIS-NN). Consequently, even if an FPU is available, the quantized model is significantly faster (Figure 2). Therefore, the combination of quantization and CMSIS-NN is superior in regard to memory footprint as well as latency without requiring the availability of an FPU. For a discussion on the effect of compiler optimizations on the latency-memory trade-off, we refer to Appendix B.1.
Non-uniform acceleration When comparing the slowest and fastest model depending on the applied optimiza- tions, we observe a consistent speedup of 13× - 16× across the MCUs for the LeNet (Table 2). On the other hand, for the ResNet, the NN is accelerated by 29× - 35×. Consequently, it is hard to predict the effect of optimizations, as the architecture of the network and supported kernels, its complexity, and the MCU architecture play a crucial role.
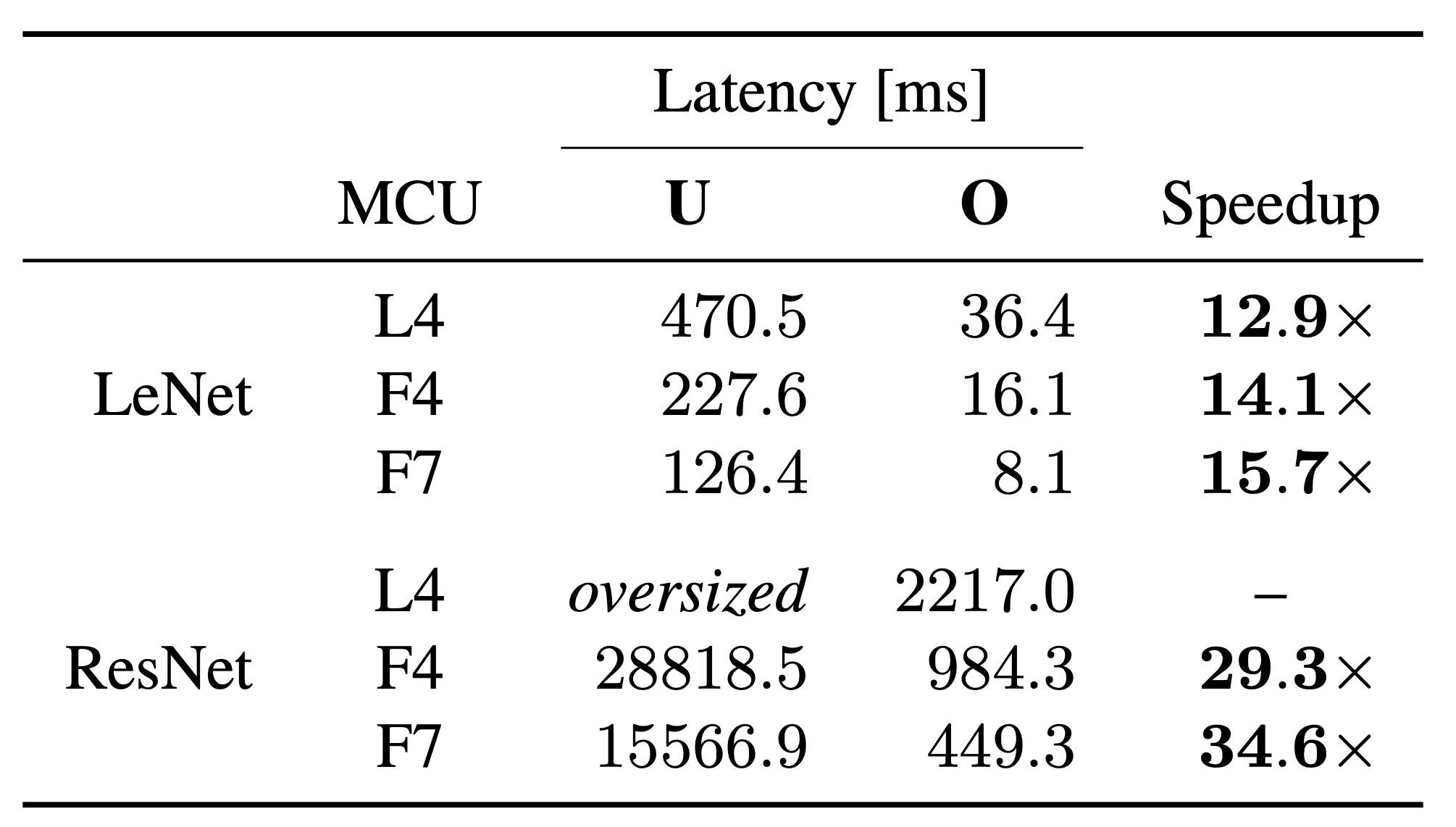
We further find that the number of parameters is an ill-suited predictor for the computational complexity of a model. ResNet has 141× more operations while only 3.4× more parameters than LeNet. To determine the predictive power of operations regarding latency, we calculate the latency ratio of LeNet and ResNet for both unoptimized (U) and optimized (O) models. For the unoptimized models, we observe a ratio of 123× - 126× (Table 3). However, when employing optimizations, the best performing models only demonstrate a relative difference of 55× - 61×. We find that optimizations result in a different scaling factor depending on the NN architecture and employed MCUs for estimating the latency from the operations. Thus, the usage of proxies depends on the target and should be empirically validated.

4.2. Energy consumption
To evaluate the expressiveness of metrics, we investigate the correlation of the inference latency and energy consumption for the respective optimizations across the MCUs. While we observe an ideal linear relationship (r = 0.9946) between them across all optimizations, it is important to note that each MCU has a different characteristic and hence offers an additional trade-off between latency and energy consumption. A look at the energy consumption of the individual layers presents a similar picture: we measure an almost linear relationship (r = 0.9995) between latency and energy consumption across our NNs and across all optimizations on a layer basis (see Appendix B.2).
This observation does not match our initial assumptions, as memory access requires magnitudes more energy than computations [20]. Therefore, we assumed that layer types that lead to more memory access (e.g., dense layers) would require a disproportional amount of energy. However, we
suspect that the increased energy cost for memory access is also seen in an increased latency. As a consequence, the inference latency is a perfect proxy for the energy consumption of the investigated MCUs. Additionally, the simple architecture of MCUs does not feature dynamic voltage scaling or power-gated sub-components of the processor, which could lead to a non-linear energy and latency relationship for more complex hardware architectures. Accordingly, all of the presented results regarding speedups and ratios for latency also apply to energy consumption.
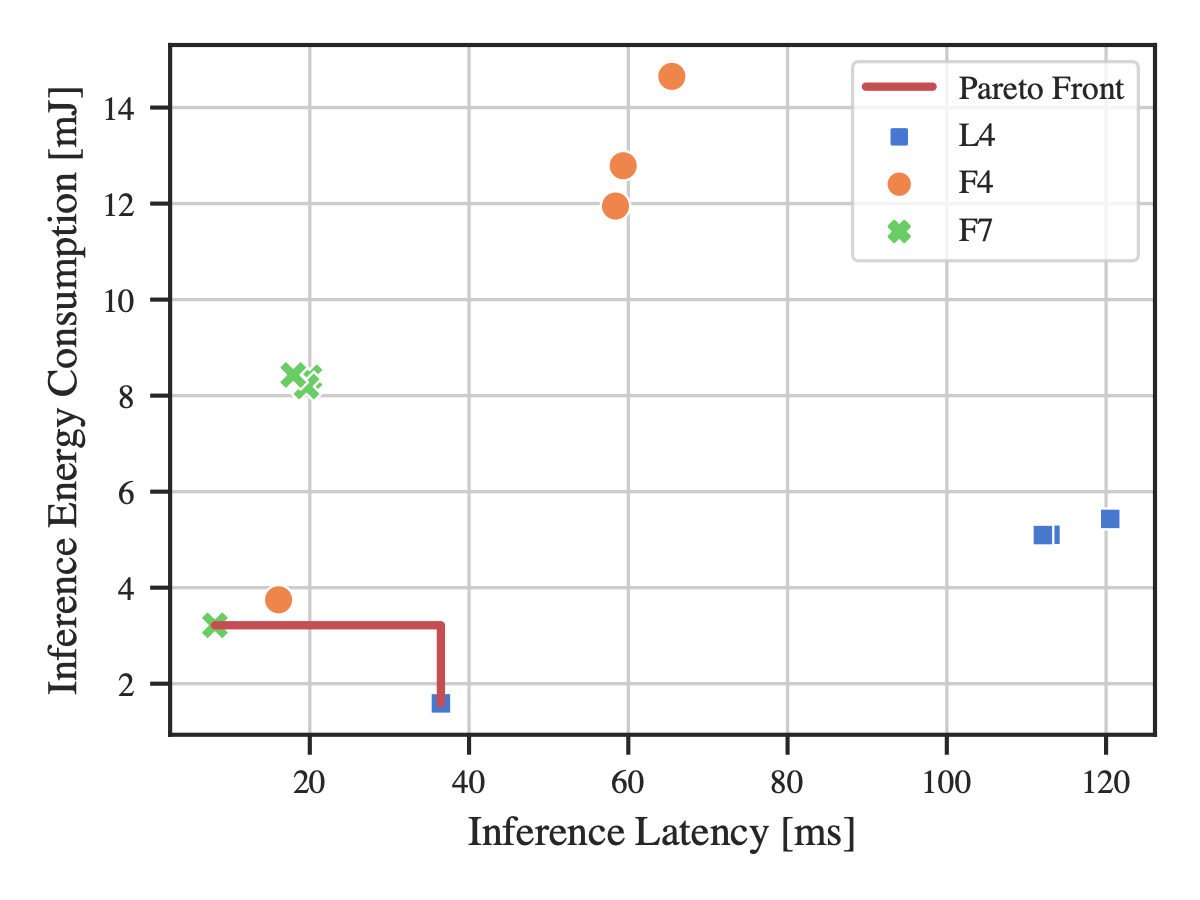
Pareto front Despite the linear dependence, we find that the choice of MCU is a trade-off between inference latency and energy consumption (Figure 3). Consequently, the ultimate choice of the target hardware depends on the specific operational requirements. We also see that not all NNs can be deployed on each MCU, as they are limited by the available Flash memory (oversized) or dynamic memory. We observe in our evaluation set that one MCU (F4) is not Pareto efficient and would deliver inferior performance for any specification. This finding stresses the importance of empirical investigations, as the selection of a Pareto efficient MCU results in faster inference and less energy consumption. As a consequence, we encourage hardware-aware testing to identify the best-fitting solution for a given scenario.
4.3. Effects of layers’ hyper-parameters
To investigate the interplay of factors in more detail, we measure the perceptible metrics with layer granularity by sweeping over the hyper-parameters of selected layers. From previous work [28], we know that CMSIS-NN is designed to leverage the underlying hardware architecture and that memory alignment plays a key role in its efficiency.
To investigate this systematically, we design benchmarking NNs which primarily consist of the layer type of interest. The hyper-parameters are iteratively incremented and deployed using our toolchain to observe their influence on the perceptible metrics. This enables us to extract guidelines for the efficient design of NNs to holistically increase the synergy between NN design, software libraries and hardware.
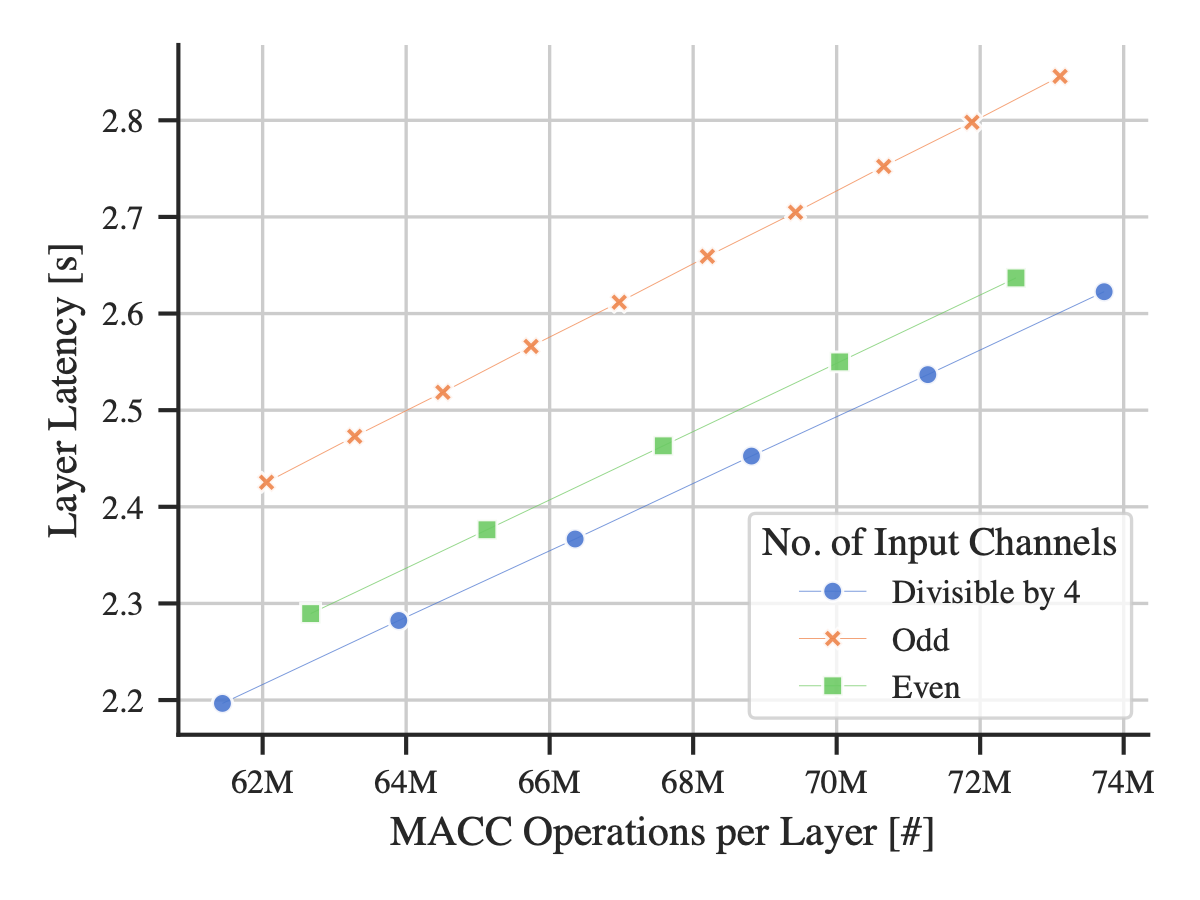
Dense layers When investigating the effect of the number of units for dense layers, we find that it is not their quantity that affects the perceptible metrics non-linearly but the number of input connections per dense unit. These inputs are consecutively accessed in memory, which is favorable for efficiency. Consequently, we observe a non-linear relationship between them and the inference latency (Figure 4). We find that this effect is sufficiently pronounced that we can achieve faster inference despite more operations by increasing the number of inputs to be even or a multiple of 4. However, we also observe a periodicity of 16 with two distinct clusters of sizes 9 and 7, whereby the first cluster is consistently more efficient. Therefore, we can increase the number of operations while decreasing latency, which simultaneously boosts accuracy and reduces perceptible metrics. This highly non-linear behavior reveals the shortcomings of operations as a proxy metric for NN complexity.
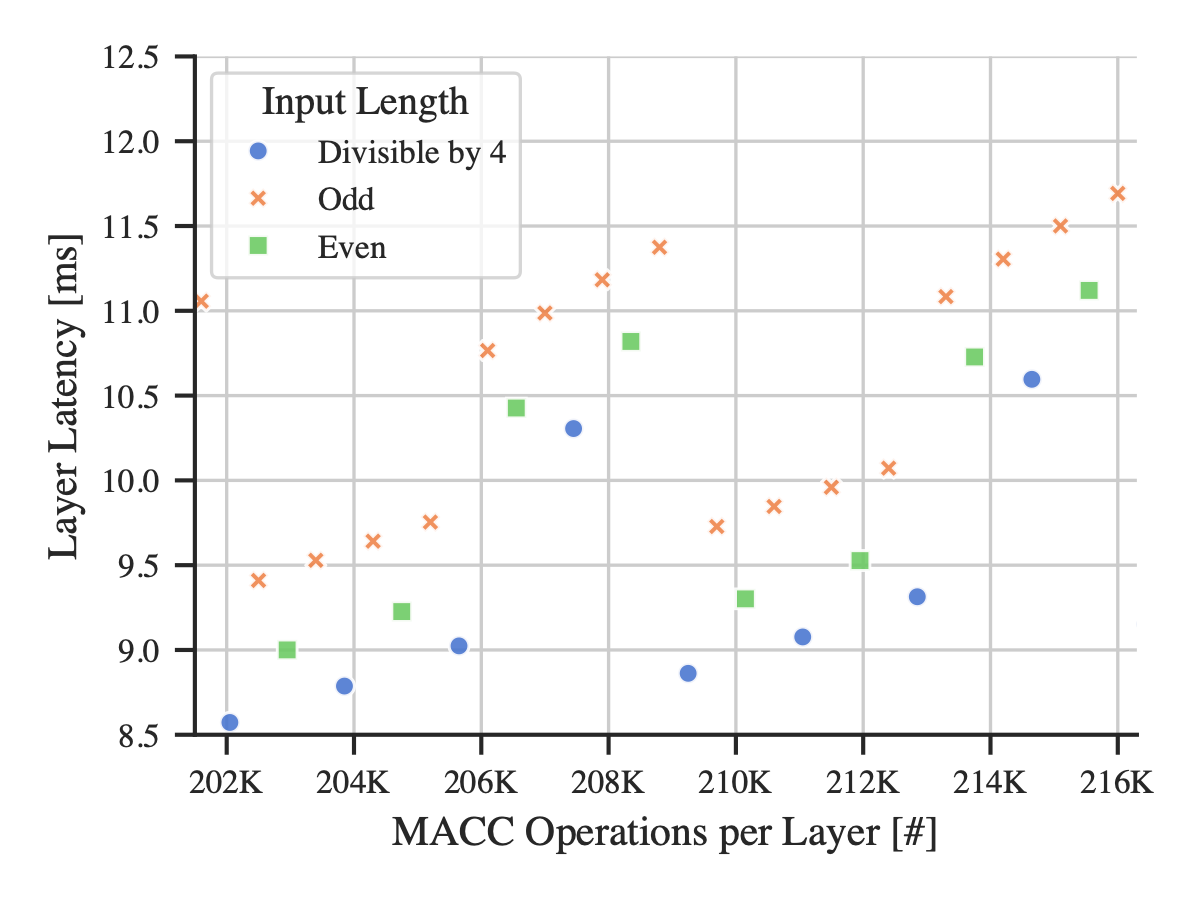
2D convolutional layers For convolutional layers, we similarly find that the input is decisive. While dense layers only consist of a single dimension as they are flattened, convolutional layers have multiple dimensions which depend on the preceding layer. We investigate the effect of the kernel size, the stride, and the number of filters of a preceding layer, as those hyper-parameters determine the dimensions of the output, and consequently the next input.
We find that the length of the input channels is the
Figure 5. For convolutional layers, the input channels are the determining hyper-parameter. If the number of input channels is divisible by 4, 8 bit memory access of the 32 bit architecture is aligned and we observe a decreased latency and energy consumption despite an increase in the number of operations.
key hyper-parameter, which is determined by the preceding layer’s number of filters. To verify this, we create a network with a static convolutional layer which we benchmark and a preceding convolutional layer where we iteratively increase the number of filters. Up to two simultaneous operations can be executed by leveraging SIMD instructions if the number is even, which we verify through an inspection of the source code. While SIMD offers the potential for up to four parallel computations, the number of MCU registers limits its exploitation in this case. Despite an increasing number of operations, we observe a reduction in our perceptible metrics if the number of input channels is even or divisible by 4, enabling us to accelerate computation by up to 7.7 % by adding a filter to the previous layer (Figure 5).
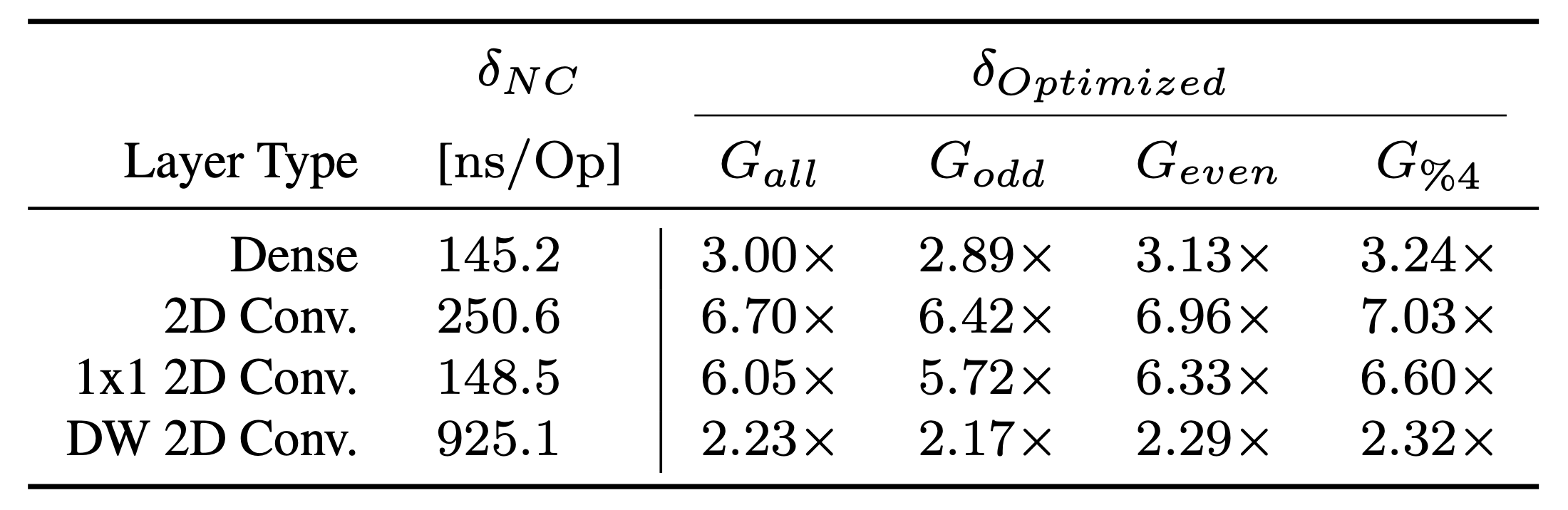
Latency per operation The latency per operation δ al- lows us to compare layers and their hyper-parameters directly based on perceptible metrics. We see that aligned memory access and the exploitation of SIMD instructions result in significant gains G (Table 4). The usage of CMSIS- NN (δOptimized) decreases the latency across all layer types compared to the hardware-agnostic implementation (δN C ). However, whether these techniques can be leveraged de- pends on the layer type. For example, depth-wise convolution cannot make use of aligned memory access due to the required, predetermined structure of the dimensions in memory. As a result, the latency of operations depends on the layer type, its hyper-parameters, and the optimizations and cannot be abstracted for proxy metrics.
4.4. Summary
Instead of optimizing layers separately, the interplay of layers reveals to be crucial. Consequently, the influence of optimizations and hyper-parameters is interdependent and a result of layer types and dimensions. However, while some layers can greatly benefit from these techniques (e.g., dense and convolution), others (e.g., depth-wise convolution) are limited in performance due to the nature of their operation and their efficiency gain is smaller. The effective costs of layers should therefore already be included during the design process when choosing layer types and dimensions.
5. Discussion
Even when building on top of existing frameworks, on-device inference and testing still require significant engineering and a deep understanding of embedded systems. We try to address this shortcoming to lower the entry burden for ML domain expert and facilitate empirical studies.
As presented in Section 4, the development of a heuristic with metrics known prior to deployment is challenging – especially when optimizations and hardware features are employed. The introduction of further optimizations such as the exploitation of sparsity [13] is likely to make matters even more complex. Operations can often be used as a rough general-purpose proxy for comparing NNs. However, especially with only subtle differences in the number of operations, it is difficult to obtain reliable efficiency estimations without implementation-aware experiments as perceptible metrics can vary significantly. Additionally, sometimes more operations can lead to decreased energy consumption and latency. Therefore, we find the verification and evaluation via deployment on hardware indispensable and present a methodology to investigate this empirically.
5.1. Design guidelines
Based on our insights, we propose a more nuanced understanding of operations and therefore recommend:
The use of quantization with a hardware-supported bitwidth (e.g., 8 bit) to leverage the underlying architecture, reduce memory size and accelerate inference.
An understanding of the kernel implementation to choose efficient layer types and dimensions (e.g. for
TFLM on Cortex-M devices with CMSIS-NN, a number of input channels which is divisible by 4).
The verification of proxy metrics by empirically measuring them and demonstrating their merit for a specific NN on the application-relevant target. Perceptible metrics are what really matters – not proxies.
5.2. Future work
Our findings could be directly applied to the manual design of efficient NN architectures. Furthermore, our toolchain can also be incorporated in NAS to explore an optimized search space dimension more efficiently (e.g. by avoiding known inferior parametrizations). The search space itself can already take the hardware architecture and quantization bit-width into account by modifying the hyperparameters accordingly and hence be reduced in size.
Additionally, our work permits researchers to evaluate candidate networks directly on perceptible metrics. We have found that the latency and energy consumption are independent of the actual value of the weights, as computation time and memory access patterns remain identical. Therefore, untrained candidate networks can already be efficiently evaluated before the computationally expensive training. Candidates which do not fit strict energy or latency criteria can be immediately discarded.
6. Conclusions
This paper demonstrates that state-of-the-art NNs can be efficiently deployed on resource-constrained devices. We show that the usage of optimizations, both generic and hardware-specific, can significantly decrease the memory footprint of NNs and accelerate their inference latency. We further demonstrate that empirical investigations are indispensable due to the variability and the interdependence of NN layers in both software and hardware. We have found that empirical implementation-aware verification is the only reliable method to obtain key performance metrics. Therefore, our developed toolchain is a cost-effective method for researchers and engineers to optimize, investigate, deploy, and benchmark NNs on ARM Cortex-M devices. In addition, we provide insights and guidelines for the design of efficient NNs. With this methodology which can be directly incorporated as a NAS component, we expect to see more efficient TinyML applications designed in symbiosis with their targeted application scenario through an implementation-aware development process.
Acknowledgments
This research was supported by the Swiss National Science Foundation under NCCR Automation, as well as a research grant of the IDEA League and the IFI program of the German Academic Exchange Service (DAAD).
References
[1] Renzo Andri, Lukas Cavigelli, Davide Rossi, and Luca Benini. YodaNN: An Ultra-Low Power Convolutional Neu- ral Network Accelerator Based on Binary Weights. In 2016 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), pages 236–241, July 2016. 2
[2] ARM Ltd. The Arm ecosystem ships a record 6.7 billion Arm-based chips in a single quarter. https://www.arm. com/company/news/2021/02/arm-ecosystem- ships-record-6-billion-arm-based-chips- in-a-single-quarter, Feb. 2021. 2
[3] ARM Ltd. ARM Cortex-M Series. https : / / developer . arm . com / ip - products / processors/cortex-m, n.d. 2
[4] ARM Ltd. Mbed OS. https://os.mbed.com/mbed- os/, n.d. 4
[5] Colby Banbury, Chuteng Zhou, Igor Fedorov, Ramon Matas, Urmish Thakker, Dibakar Gope, Vijay Janapa Reddi, Matthew Mattina, and Paul Whatmough. MicroNets: Neural Network Architectures for Deploying TinyML Applications on Commodity Microcontrollers. Proceedings of Machine Learning and Systems, 3, 2021. 1, 2
[6] Colby R. Banbury, Vijay Janapa Reddi, Max Lam, William Fu, Amin Fazel, Jeremy Holleman, Xinyuan Huang, Robert Hurtado, David Kanter, Anton Lokhmotov, David Pat- terson, Danilo Pau, Jae-sun Seo, Jeff Sieracki, Urmish Thakker, Marian Verhelst, and Poonam Yadav. Bench- marking TinyML Systems: Challenges and Direction. arXiv:2003.04821 [cs], May 2020. 3
[7] Ron Banner, Yury Nahshan, and Daniel Soudry. Post train- ing 4-bit quantization of convolutional networks for rapid- deployment. Advances in Neural Information Processing Systems, 32, 2019. 2
[8] Hadjer Benmeziane, Kaoutar El Maghraoui, Hamza Ouarnoughi, Smail Niar, Martin Wistuba, and Naigang Wang. A Comprehensive Survey on Hardware-Aware Neu- ral Architecture Search. arXiv:2101.09336 [cs], Jan. 2021. https://arxiv.org/abs/2101.09336. 2
[9] Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. Once for all: Train one network and specialize it for efficient deployment. In International Conference on Learning Representations, 2020. https://arxiv.org/ pdf/1908.09791.pdf. 1, 2
[10] XinChen,LingxiXie,JunWu,LonghuiWei,YuhuiXu,and Qi Tian. Fitting the Search Space of Weight-sharing NAS with Graph Convolutional Networks. arXiv:2004.08423 [cs, stat], Apr. 2020. https://arxiv.org/abs/2004. 08423. 2
[11] Robert David, Jared Duke, Advait Jain, Vijay Janapa Reddi, Nat Jeffries, Jian Li, Nick Kreeger, Ian Nappier, Meghna Na- traj, Shlomi Regev, Rocky Rhodes, Tiezhen Wang, and Pete Warden. TensorFlow Lite Micro: Embedded Machine Learn- ing on TinyML Systems. arXiv:2010.08678 [cs], Mar. 2021. https://arxiv.org/abs/2010.08678. 2, 4
[12] Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural Architecture Search. In Automated Machine Learn- ing, pages 63–77. Springer International Publishing, Cham, 2019. 2
[13] Igor Fedorov, Ryan P Adams, Matthew Mattina, and Paul Whatmough. SpArSe: Sparse architecture search for CNNs on resource-constrained microcontrollers. In Advances in Neural Information Processing Systems 32, pages 4977– 4989. Curran Associates, Inc., 2019. 8
[14] Song Han, Huizi Mao, and William J. Dally. Deep com- pression: Compressing deep neural network with pruning, trained quantization and huffman coding. In 4th Interna- tional Conference on Learning Representations, San Juan, Puerto Rico, 2016. https://arxiv.org/abs/1510. 00149. 1, 2
[15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), pages 770–778, June 2016. 5
[16] Yihui He, Xiangyu Zhang, and Jian Sun. Channel Pruning for Accelerating Very Deep Neural Networks. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 1398–1406, Oct. 2017. 1, 2
[17] Lennart Heim, Andreas Biri, Zhongnan Qu, and Lothar Thiele. Measuring what Really Matters: Optimizing Neu- ral Networks for TinyML - Measurement data repository. https://gitlab.ethz.ch/tec/public/tflm- toolchain, Apr. 2021. 4
[18] Lennart Heim, Andreas Biri, Zhongnan Qu, and Lothar Thiele. Measuring what Really Matters: Optimizing Neu- ral Networks for TinyML - Software repository: Toolchain. https://gitlab.ethz.ch/tec/public/tflm- toolchain, Apr. 2021. 4
[19] Geoffrey Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network. In NIPS Deep Learning and Representation Learning Workshop, 2015. https:// arxiv.org/abs/1503.02531. 1
[20] Mark Horowitz. Computing’s energy problem (and what we can do about it). In 2014 IEEE International Solid-State Cir- cuits Conference Digest of Technical Papers (ISSCC), pages 10–14, Feb. 2014. 6
[21] Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco An- dreetto, and Hartwig Adam. MobileNets: Efficient Convo- lutional Neural Networks for Mobile Vision Applications. arXiv:1704.04861 [cs], Apr. 2017. https : / / arxiv . org/abs/1704.04861. 2
[22] Chi-Hung Hsu, Shu-Huan Chang, Jhao-Hong Liang, Hsin- Ping Chou, Chun-Hao Liu, Shih-Chieh Chang, Jia-Yu Pan, Yu-Ting Chen, Wei Wei, and Da-Cheng Juan. MONAS: Multi-Objective Neural Architecture Search using Rein- forcement Learning. arXiv:1806.10332 [cs, stat], Dec. 2018. https://arxiv.org/abs/1806.10332. 2
[23] Forrest N. Iandola, Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, and Kurt Keutzer. SqueezeNet: AlexNet-level accuracy with 50x fewer param- eters and <0.5MB model size. arXiv:1602.07360 [cs], Nov. 2016. https://arxiv.org/abs/1602.07360. 2
[24] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry
9
Kalenichenko. Quantization and Training of Neural Net- works for Efficient Integer-Arithmetic-Only Inference. In 2018 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 2704–2713, June 2018. 1, 2
[25] Wenjun Jiang, Hongfei Xue, Chenglin Miao, Shiyang Wang, Sen Lin, Chong Tian, Srinivasan Murali, Haochen Hu, Zhi Sun, and Lu Su. Towards 3D human pose construction using wifi. In Proceedings of the 26th Annual International Con- ference on Mobile Computing and Networking, MobiCom ’20, pages 1–14, New York, NY, USA, Apr. 2020. Associa- tion for Computing Machinery. 1
[26] Felix Johnny and Fredrik Knutsson. CMSIS-NN & Op- timizations for Edge AI. https://cms.tinyml. org/wp- content/uploads/talks2021/tinyML_ Talks_Felix_Johnny_Thomasmathibalan_and_ Fredrik_Knutsson_210208.pdf, Feb. 2021. 3
[27] Norman P. Jouppi, Cliff Young, Nishant Patil, David Patter- son, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, Rick Boyle, Pierre-luc Cantin, Clifford Chao, Chris Clark, Jeremy Coriell, Mike Daley, Matt Dau, Jeffrey Dean, Ben Gelb, Tara Vazir Ghaem- maghami, Rajendra Gottipati, William Gulland, Robert Hag- mann, C. Richard Ho, Doug Hogberg, John Hu, Robert Hundt, Dan Hurt, Julian Ibarz, Aaron Jaffey, Alek Ja- worski, Alexander Kaplan, Harshit Khaitan, Daniel Kille- brew, Andy Koch, Naveen Kumar, Steve Lacy, James Laudon, James Law, Diemthu Le, Chris Leary, Zhuyuan Liu, Kyle Lucke, Alan Lundin, Gordon MacKean, Adriana Maggiore, Maire Mahony, Kieran Miller, Rahul Nagarajan, Ravi Narayanaswami, Ray Ni, Kathy Nix, Thomas Nor- rie, Mark Omernick, Narayana Penukonda, Andy Phelps, Jonathan Ross, Matt Ross, Amir Salek, Emad Samadi- ani, Chris Severn, Gregory Sizikov, Matthew Snelham, Jed Souter, Dan Steinberg, Andy Swing, Mercedes Tan, Gre- gory Thorson, Bo Tian, Horia Toma, Erick Tuttle, Vijay Va- sudevan, Richard Walter, Walter Wang, Eric Wilcox, and Doe Hyun Yoon. In-datacenter performance analysis of a tensor processing unit. In 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), pages 1–12, June 2017. 1, 2, 3
[28] Liangzhen Lai, Naveen Suda, and Vikas Chandra. CMSIS- NN: Efficient Neural Network Kernels for Arm Cortex-M
CPUs. arXiv:1801.06601 [cs], Jan. 2018. https : / / arxiv.org/abs/1801.06601. 4, 5, 6
[29] Liangzhen Lai, Naveen Suda, and Vikas Chandra. Not All Ops Are Created Equal! In SysML Conference 2018, Stan- ford, CA, USA, Feb. 2018. https://arxiv.org/abs/ 1801.04326. 3
[30] Yann LeCun, Le ́eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recog- nition. Proceedings of the IEEE, 86(11):2278–2324, Nov. 1998. 5
[31] Sheng Li, Mingxing Tan, Ruoming Pang, Andrew Li, Liqun Cheng, Quoc Le, and Norman P. Jouppi. Search- ing for Fast Model Families on Datacenter Accelerators. arXiv:2102.05610 [cs, eess], Feb. 2021. https:// arxiv.org/abs/2102.05610. 2
[32] Edgar Liberis, Łukasz Dudziak, and Nicholas D. Lane. uNAS: Constrained Neural Architecture Search for Micro-
controllers. arXiv:2010.14246 [cs], Dec. 2020. https:
//arxiv.org/abs/2010.14246. 1, 2
[33] Darryl Lin, Sachin Talathi, and Sreekanth Annapureddy. Fixed Point Quantization of Deep Convolutional Networks. In International Conference on Machine Learning, pages
2849–2858. PMLR, June 2016. 1, 2
[34] JiLin,Wei-MingChen,YujunLin,JohnCohn,ChuangGan,
and Song Han. MCUNet: Tiny Deep Learning on IoT De- vices. Advances in Neural Information Processing Systems, 33:11711–11722, 2020. 2
[35] Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: Differentiable Architecture Search. arXiv:1806.09055 [cs, stat], Apr. 2019. https://arxiv.org/abs/1806. 09055. 2
[36] Wenqi Liu and Kun Zeng. SparseNet: A Sparse DenseNet for Image Classification. arXiv:1804.05340 [cs], Apr. 2018. https://arxiv.org/abs/1804.05340. 2
[37] Matthias Meyer, Timo Farei-Campagna, Akos Pasztor, Reto Da Forno, Tonio Gsell, Je ́rome Faillettaz, Andreas Vieli, Si- mon Weber, Jan Beutel, and Lothar Thiele. Event-triggered Natural Hazard Monitoring with Convolutional Neural Net- works on the Edge. In 2019 18th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), pages 73–84, Apr. 2019. 1
[38] OpenAI. AI and Compute. https://openai.com/ blog/ai-and-compute/, May 2018. 1, 2
[39] Zhongnan Qu, Cong Liu, Junfeng Guo, and Lothar Thiele. Deep Partial Updating. arXiv:2007.03071 [cs, stat], Oct. 2020. https://arxiv.org/abs/2007.03071. 1
[40] Zhongnan Qu, Zimu Zhou, Yun Cheng, and Lothar Thiele. Adaptive Loss-Aware Quantization for Multi-Bit Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7988–7997, 2020. 1, 2
[41] LukasSigrist,AndresGomez,RomanLim,StefanLippuner, Matthias Leubin, and Lothar Thiele. Measurement and val- idation of energy harvesting IoT devices. In Proceedings of the 2017 Design, Automation & Test in Europe Conference & Exhibition, Lausanne, Switzerland, Mar. 2017. 4, 5
[42] STMicroelectronics. DISCO-STM32F469NI.
https : / / www . st . com / en / evaluation -
tools/32f469idiscovery.html, n.d. 5
[43] STMicroelectronics. NUCLEO-F767ZI. https : / / www.st.com/en/evaluation-tools/nucleo-
f767zi.html, n.d. 5
[44] STMicroelectronics. NUCLEO-L496ZG. https : / /
www.st.com/en/evaluation-tools/nucleo-
l496zg.html, n.d. 5
[45] Emma Strubell, Ananya Ganesh, and Andrew McCallum.
Energy and policy considerations for deep learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3645–3650, Florence, Italy, July 2019. Association for Computational Linguistics. 1
[46] Vivienne Sze. How to Evaluate Efficient Deep Neural Network Approaches. https://workshop-edlcv. github.io/slides/Sze.pdf, June 2020. 3
10
[47] Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, and Joel S. Emer. Efficient Processing of Deep Neural Networks. Syn- thesis Lectures on Computer Architecture, 15(2):1–341, June 2020. 3
[48] Mingxing Tan and Quoc Le. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In International Conference on Machine Learning, pages 6105–6114. PMLR, May 2019. 2
[53] Juheon Yi, Sunghyun Choi, and Youngki Lee. EagleEye: Wearable camera-based person identification in crowded ur- ban spaces. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking, Mobi- Com ’20, pages 1–14, New York, NY, USA, Apr. 2020. As- sociation for Computing Machinery. 1
[54] Xinyi Zhang, Weiwen Jiang, Yiyu Shi, and Jingtong Hu. When Neural Architecture Search Meets Hardware Imple- mentation: From Hardware Awareness to Co-Design. In 2019 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), pages 25–30, July 2019. 2
[55] Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. ShuffleNet: An extremely efficient convolutional neural net- work for mobile devices. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6848– 6856, 2018. 2
[56] Zhuangwei Zhuang, Mingkui Tan, Bohan Zhuang, Jing Liu, Yong Guo, Qingyao Wu, Junzhou Huang, and Jinhui Zhu. Discrimination-aware channel pruning for deep neural net- works. In Advances in Neural Information Processing Sys- tems 31, pages 881–892. Curran Associates, Inc., 2018. 2
[49] TensorFlow. TensorFlow. tensorflow.org/, n.d. 4
https : / / www .
[50] TensorFlow. TensorFlow Lite. https : / / www . tensorflow.org/lite, n.d. 4, 5
[51] TensorFlow. TensorFlow Lite for Microcontrollers.
https : / / www . tensorflow . org / lite /
microcontrollers, n.d. 4
[52] Bichen Wu, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang,
Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, Yangqing Jia, and Kurt Keutzer. FBNet: Hardware-Aware Effi- cient ConvNet Design via Differentiable Neural Architec- ture Search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10734– 10742, 2019. 2
11