Huawei's next AI Accelerator: Ascend 910C
Huawei's next AI accelerator—the Ascend 910C—is entering production. It's China's best AI chip.

This is a cross-post of my X thread.
Huawei's next AI accelerator—the Ascend 910C—is entering production. It's China's best AI chip. Thanks to backdoor sourcing, we could easily see 1M H100-equivalents in China this year. Here’s what we know about its performance and strategic implications. Spoiler: selectively competitive.
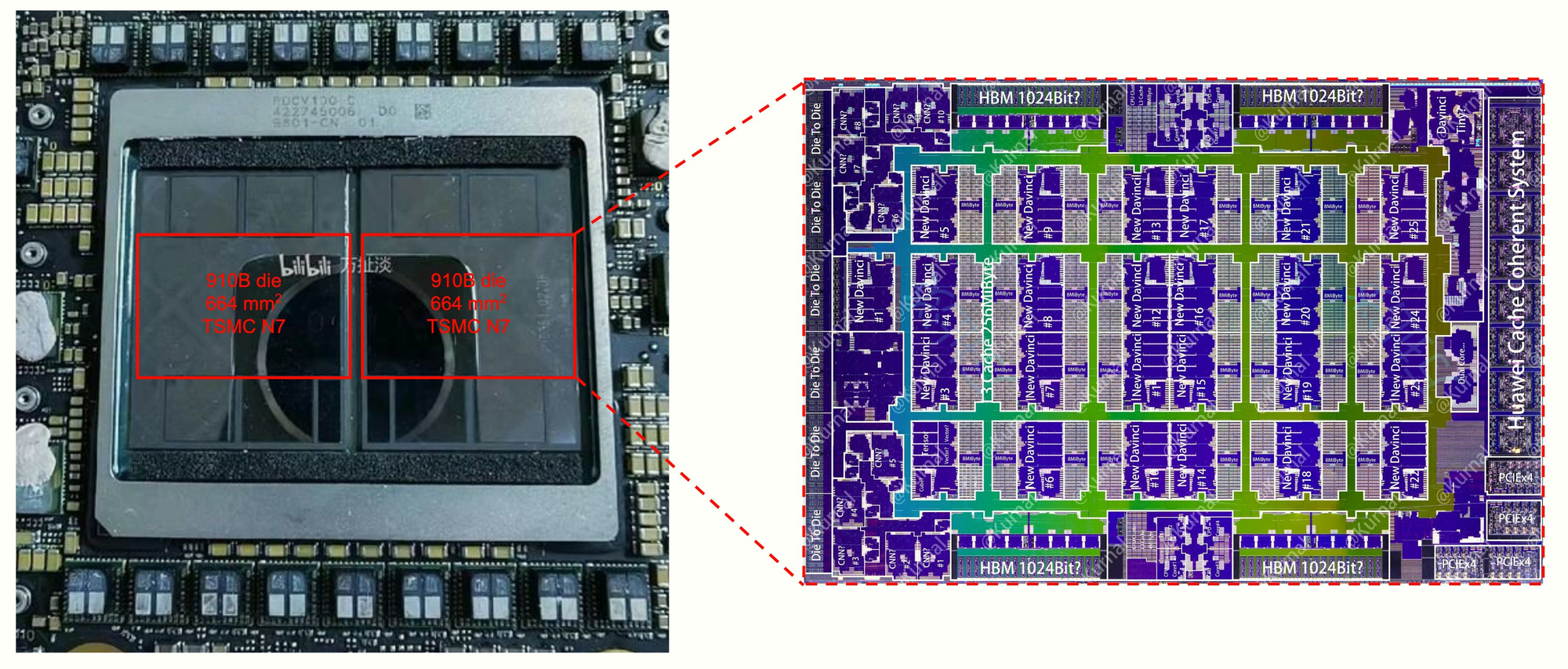
The 910C is basically two co-packaged Ascend 910Bs, China's best current-gen accelerator. But there's a twist: most (potentially all) of these chips weren't produced domestically—they were illicitly procured from TSMC despite export controls.

I'd expect the 910C to achieve ~800 TFLOP/s at FP16 and ~3.2 TB/s memory bandwidth. This makes it only ≈80% as performant as NVIDIA's previous-generation H100 (from 2022) while using 60% more logic die area.
Unlike NVIDIA's advanced packaging in the B100/200 series, the 910C likely uses a less technically sophisticated approach with two separate silicon interposers connected by an organic substrate.
This could result in 10-20x less die-to-die bandwidth compared to NVIDIA's solution. This needs to be overcome by engineering. If the bandwidth is that low, it's not really one chip and engineers using that chip need to take it into account.
The technical gap is substantial: compared to NVIDIA's B200 that will go into data centers this year, the 910C has ~3x less computational performance and ~2.5x less memory bandwidth (assuming HBM2E which we know they've stockpiled; HBM3 is also possible). It is also a lot more power-inefficient.
Huawei likely illicitly obtained close to 3M Ascend dies at 7nm from TSMC this year (now fixed via foundry due diligence rule). The PRC has also stockpiled HBM2E memory from Samsung (which is now under export controls but they had a chance to stockpile before)—enough for potentially 1.4M 910C accelerators (2 dies per accelerator).
In October 2024, it was widely reported that TSMC had fabricated a large number of export-controlled AI accelerator dies for Huawei. The new foundries rules are aimed at preventing Chinese firms from circumventing export controls in a similar manner. 1/ pic.twitter.com/OgEPz4jRbQ
— Sihao Huang (@Huang_Sihao) January 15, 2025
In addition, @Gregory Allen just shared some speculations on their own advanced production capacity. They should be able to produce 910B and 910C dies at the 7nm node. But we've yet to see a teardown of a 910B or 910C actually produced domestically (I think it's possible but expect the majority to come illegally from TSMC).

While impressive, this still falls short of what the West produces, with at least 5x the number of chips in 2025 and 10-20x the computing power. The US compute advantage in total remains strong.
Having 10x more compute is cool and a key strategic advantage, as I've argued before. But it's different if it's disbursed across many companies. China can centralize more easily than we do... that's a key thing to watch out for.
This means China will be competitive in many domains. Expect competitive models and more gains especially from reasoning. However, the next pre-training generation might require new and bigger clusters needing tens of thousands of chips. Furthermore, to gain from those models, countries will want to deploy them to millions of users, or run a large number of AI agents autonomously, where total compute quantity still matters. That’s where we will see the impact of these controls.
To summarize: Per-chip performance isn't impressive—achieving only 80% of the H100 with a 4 year delay. BUT, they can overcome it by clustering more chips given the substantial amount of illicit dies procured from TSMC (and potentially smaller amounts from SMIC). There will be competitive models from China—the talent and compute are there.
This doesn't mean export controls failed; it's just critical to understand what China can deliver, what export controls allow, and what they do not. I've shared before all the complementary approaches we need—AI resilience, AI for defense, and more. Will write this all up together at some point to pre-empt another DeepSeek-style freakout.